Visualisation des proportions
1 Introduction
Dans un premier temps, on va créer des graphiques pour représenter les proportions des différentes modalités des variables.
2 Barres empilées
On va prendre l’exemple des catégories de routes (dans la base lieux), pour visualiser le nombre d’accidents en fonction des différentes catégories de routes.
2.1 Transformation des données
On peut d’abord calculer le nombre d’accidents par type de routes.
2.2 Création des barres
Puis on peut utiliser ggplot2 pour créer une barre empilée.
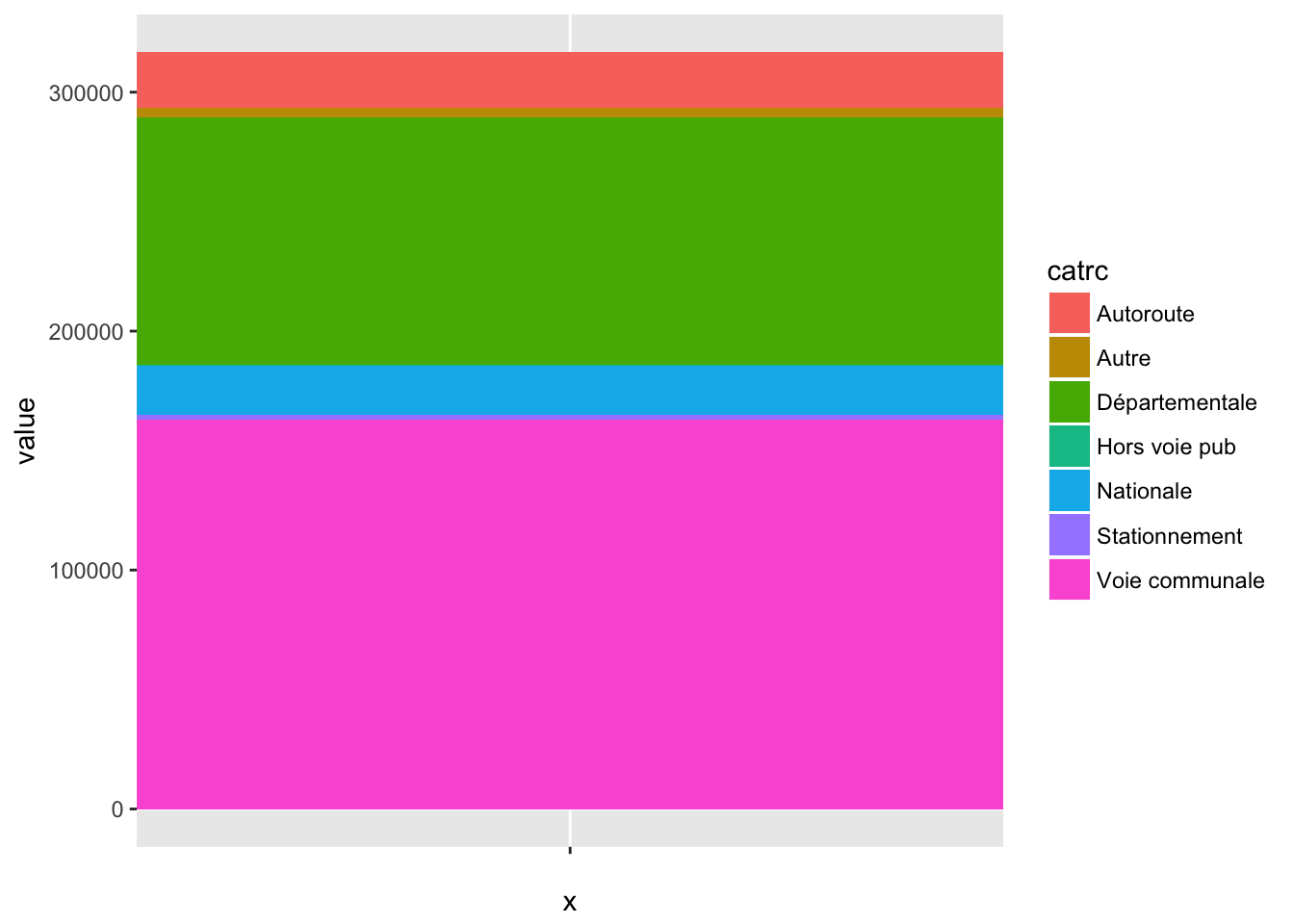
- On constate que les catégories sont classées par défaut dans l’ordre alphabétique. On peut modifier l’ordre pour que ce soit dans l’ordre du nombre d’accidents.
- Au passage, on peut aussi améliorer les différents titres.
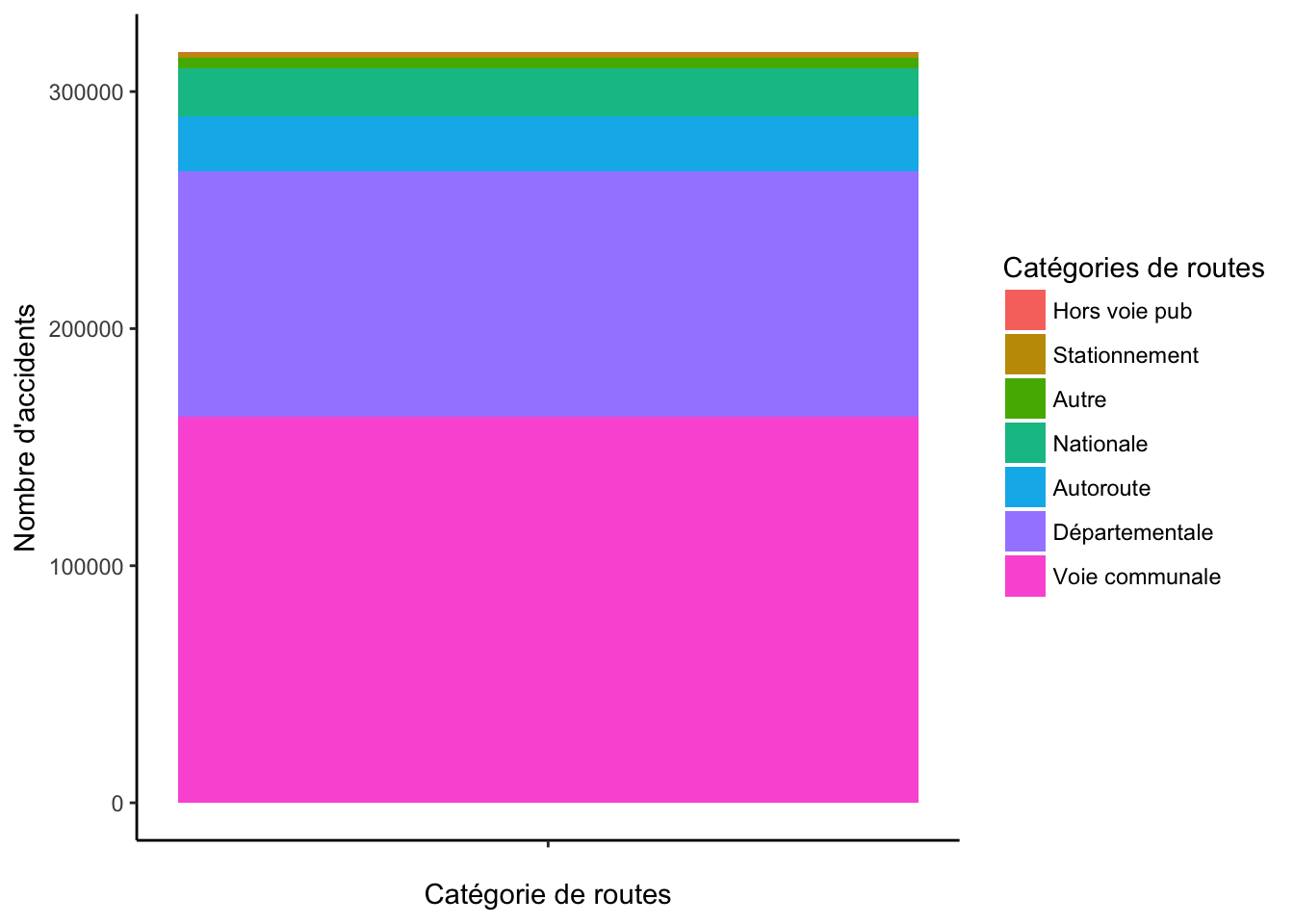
3 Camembert
Le camembert est très souvent utilisé pour représenter les proportions d’une variable selon les modalités présentes.
3.1 Transformation du système de coordonnées
Pour avoir le camembert, il suffit de changer de système de coordonnées:
- dans le cas des barres empilées, on utilise le système cartésien: l’axis y représente le nombre d’accident
- dans le cas du camembert, on doit représente les proportions avec l’angle de rotation.
Pour faciliter l’affichage du pourcentage, on va d’abord calculer les pourcentages dans la table des données.
3.2 Création du camembert
A partir des barres empilées, il suffit de changer le système des coordonnées en coord_polar pour créer un camembert.
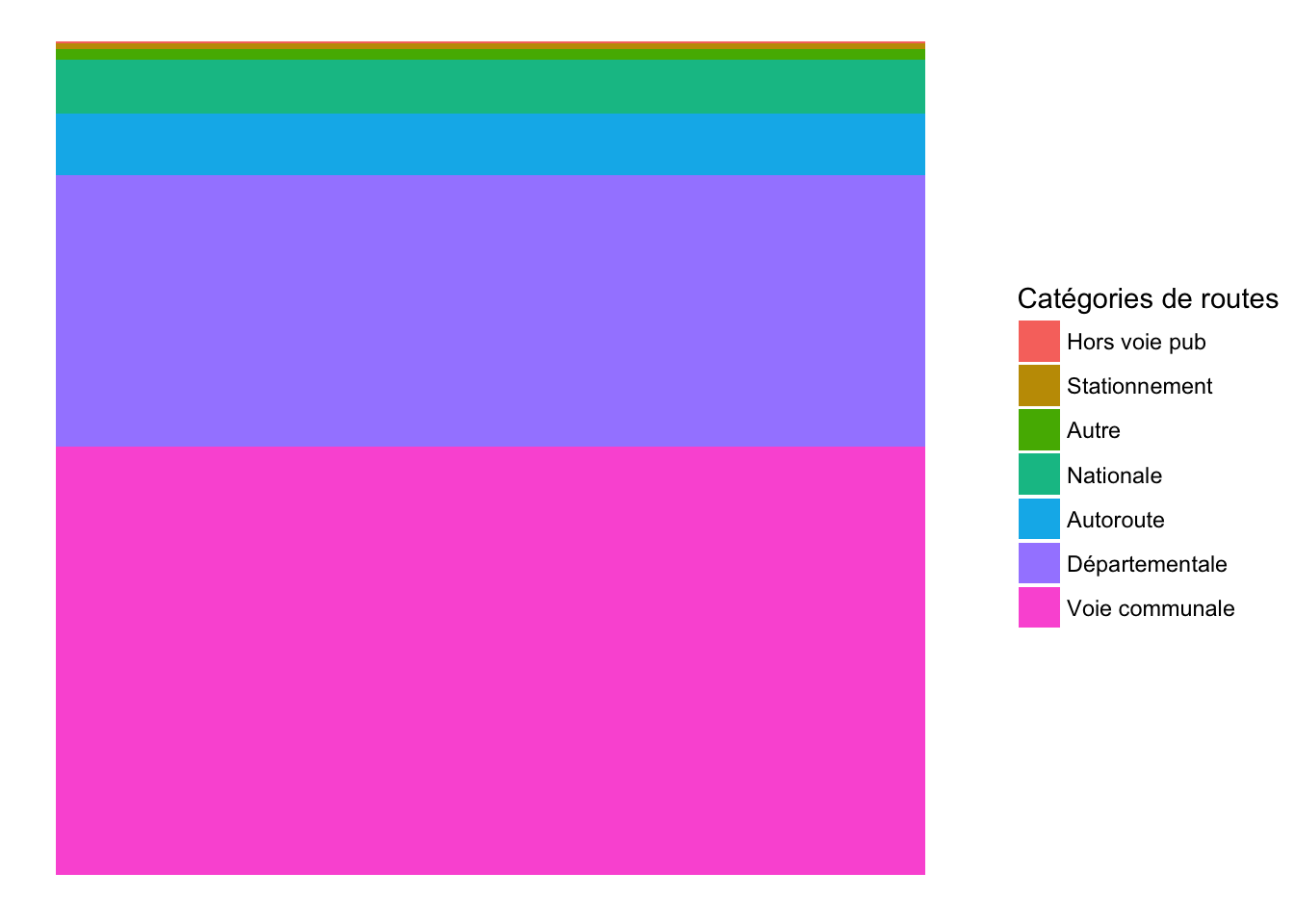
- Afin de bien comprendre la transformation polaire, on peut créer dans un premier temps un barplot empilé. Dans ce barplot, x est vide, y représente les pourcentages. Les différentes couleurs représentent les catégories de routes.
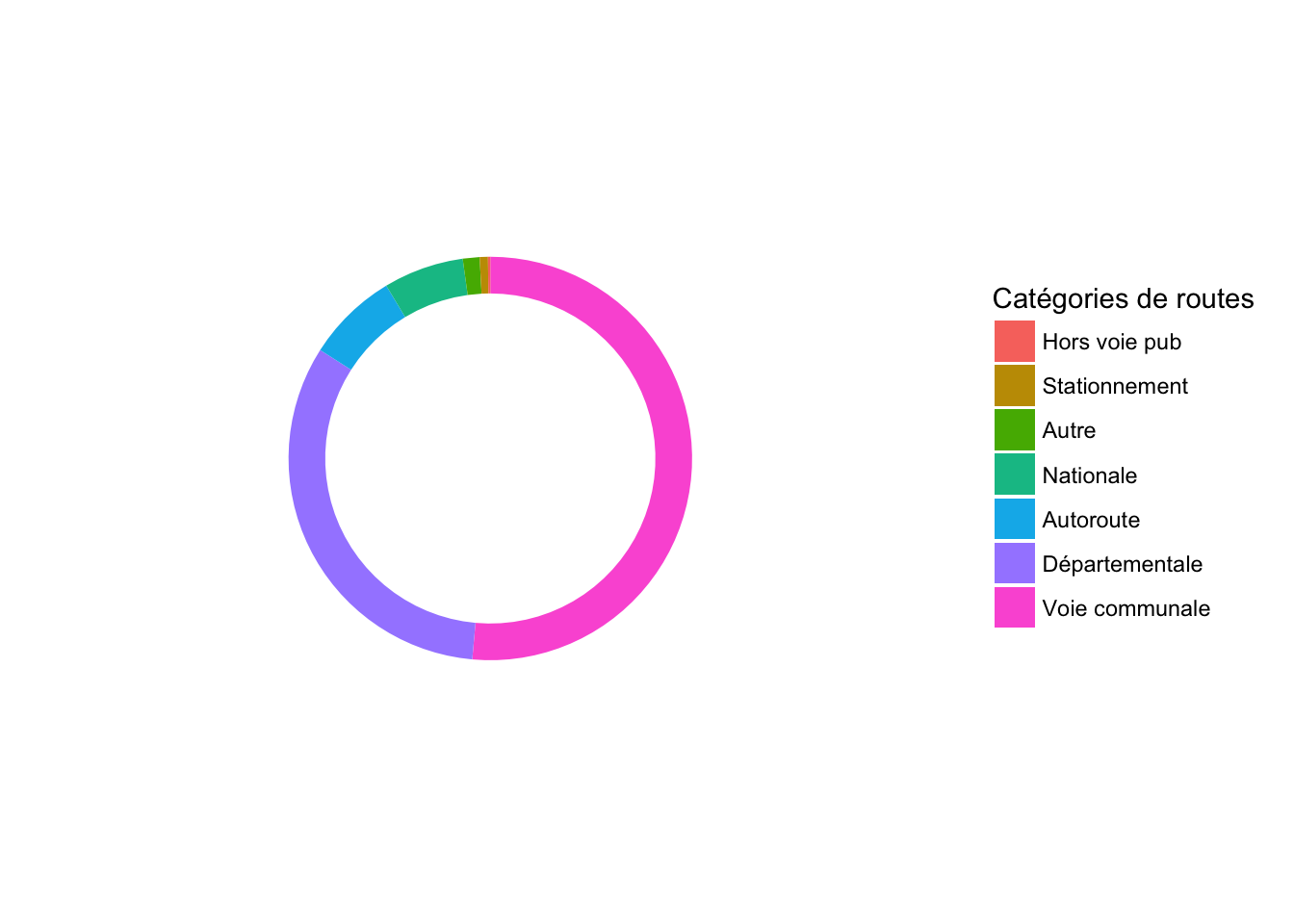
- Ensuite, on peut ajouter la transformation polaire, en précisant que le paramètre theta est représenté par y (qui est le pourcentage). C’est comme si vous prenez les deux bouts du barplot pour former un anneau ou beignet (donut chart, en anglais). Et il est possible de régler la largeur de cet anneau en jouant sur le paramètre width. Vous pouvez ainsi remarquer que l’anneau devient un dique si
width=1.
3.3 Afficher pourcentages
Pour faciliter la lecture, on peut afficher les pourcentages de chaque part.
On peut utiliser geom_text. Comme on voit dans le camembert suivant, les textes se chevauchent.
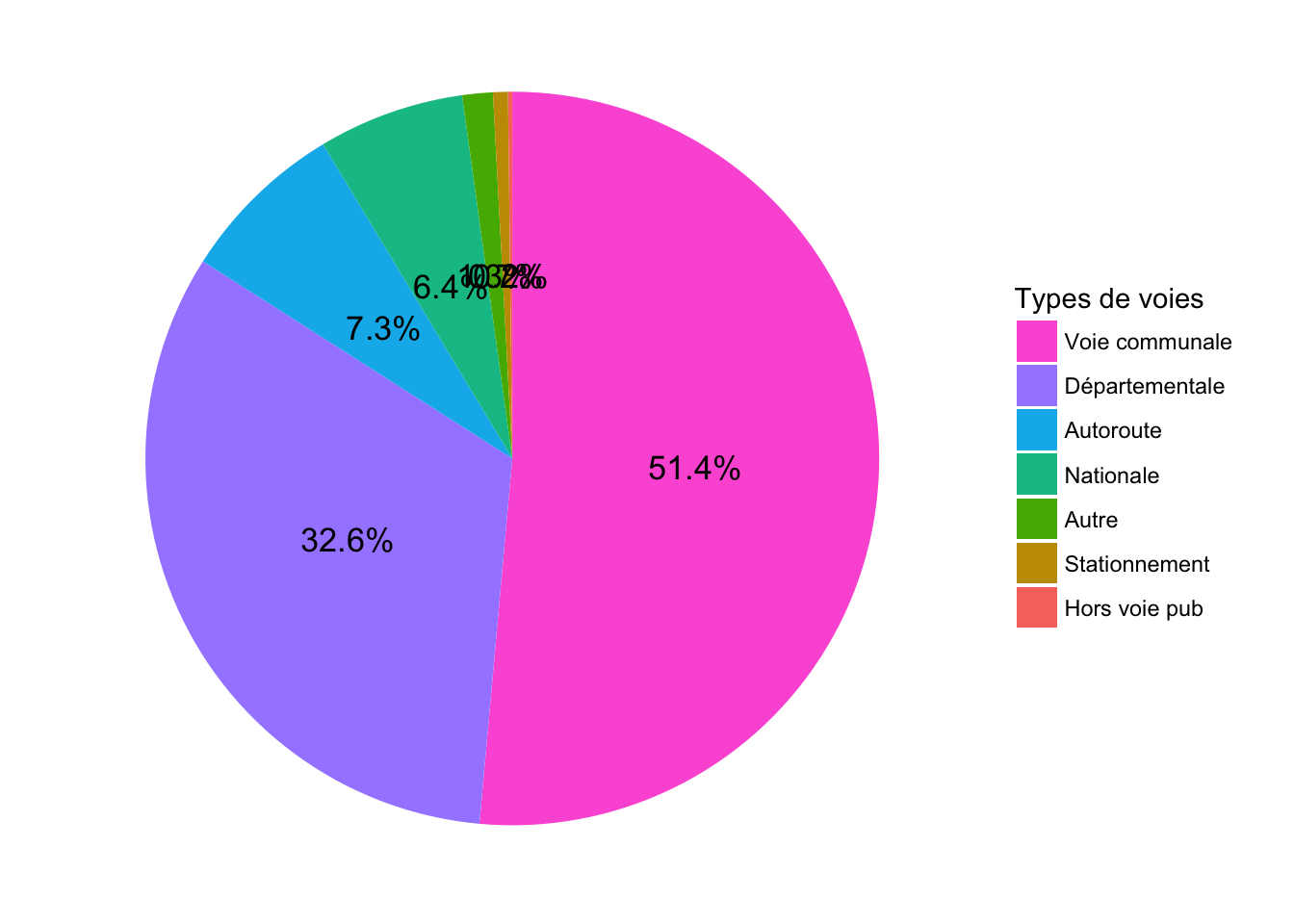
Pour résoudre le problème, on peut utiliser le package ggrepel.
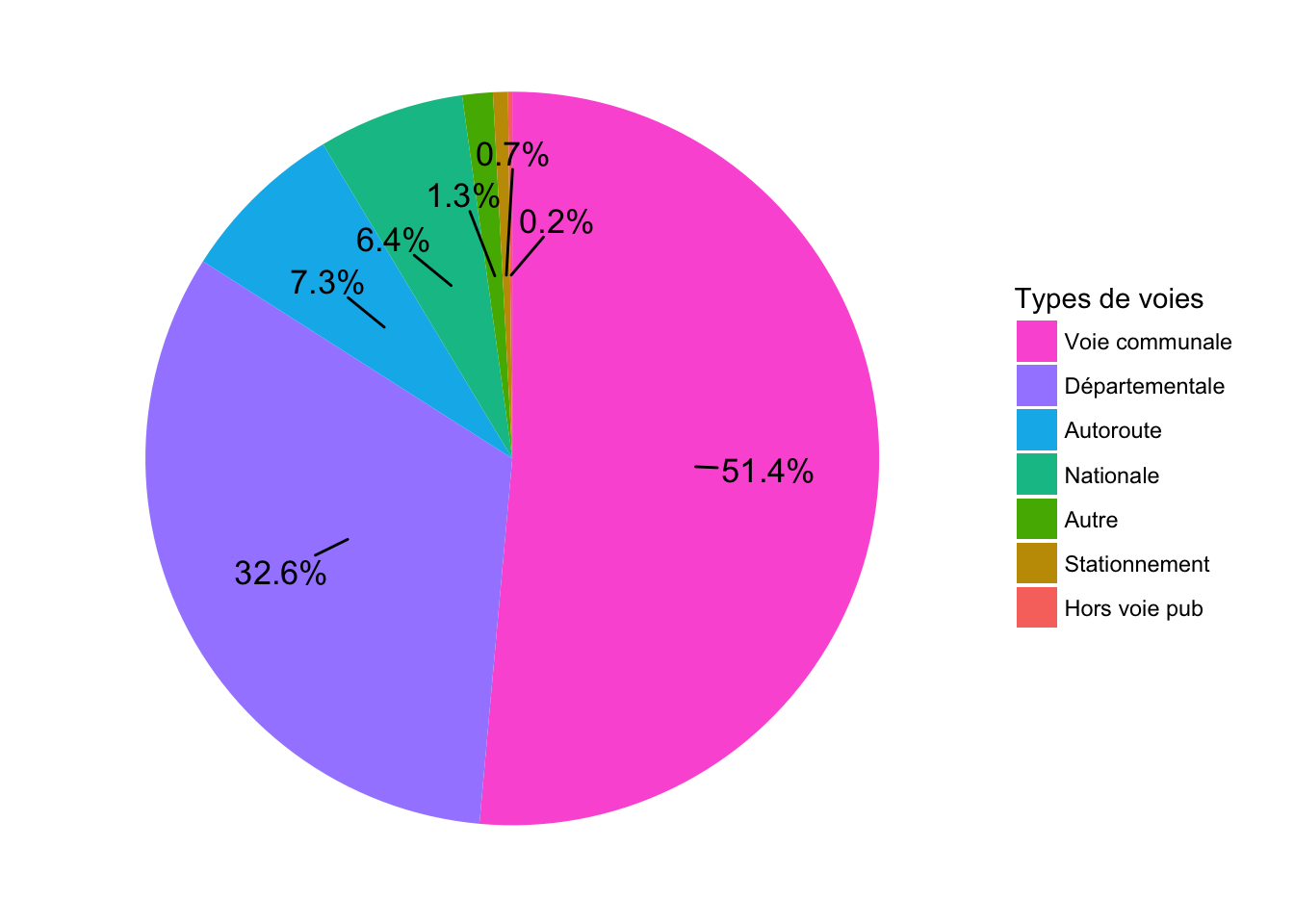
4 Sunburst
Dans un camembert comme montre l’exemple précédent, on ne peut pas afficher plusieurs variables. Si veut afficher les sous-catégories d’une catégorie donnée, on peut utiliser un sunburst.
Dans l’exemple suivant, on choisit de représenter le situation de l’accident, avec la variable situ dans la base lieux.
4.1 Transformation des données
Pour la réalisation du sunburst précédent, on doit d’abord combiner plusieurs bases de données.
Ensuite, on doit regrouper les données en comptant le nombre d’occurrences pour les caractéristiques qu’on souhaite étudier:
4.2 Sunburst (D3.js)
On peut utiliser le sunburst de la librairerie D3.js.
4.3 Remarque
En explorant le sunburst, on peut se poser la question suivante: on peut arriver à visualiser et afficher le sous pourcentage des sous-catégories (situation de l’accident) en fonction d’une catégorie (type de route); mais on n’arrive pas à visualiser la différences des proportions des situations de l’accident en fonction des types de voie.
Pour cela, on va utiliser les graphiques qui permettent de faire des comparaisons, dans la partie suivante.
5 Treemap
Le treemap permet de voir les proportions et la hiérarchie des catégories. En particulier, un treemap interactif permet d’explorer efficacement les données catégoriques.
5.1 Transformation de données
Dans un treemap, on peut souvent représenter une variable avec la couleur des rectangles.
Dans l’exemple, on va utiliser la couleur pour représenter la gravité des accidents. Ainsi, dans un premier temps, on doit choisir des valeurs pour représenter les différents niveaux de gravité. En entreprise, on a les montants des sinistres qui peuvent être représentés en couleur.
Le niveau de treemap peut être plus ou moins profond, dans l’exemple suivant, on va afficher: les catégories de routes catrc, la situation des accidents situc, l’intersection intc et le niveau de gravité pour représenter la couleur.
Pour cela, on doit fusionner les différentes bases pour avoir ces informations.
5.2 Création de treemap
On peut alors créer le treemap suivant, en précisant les différents paramètres dans treemap
- index: on peut préciser les différentes variables catégorique à prendre en compte pour la construction du treemap. Par exemple, on choisit dans l’ordre: les catégories de routes, les situations des accidents, et les intersections.
- Ainsi, le grand rectangle est découpé par des traits épais en différentes catégories de routes: Voie communale, départementale, autoroute, etc.
- Ensuite, chaque petit rectangle est découpé par des traits moins épais en situations d’accidents: Chaussée, accotement, troittoir, etc.
- A la fin, on a les intersections: Hors int (hors intersection), int T (intersection en T), int X (intersection en X), etc.
- vSize: la taille des rectangles est représentée par le nombre d’accidents
- vColor: la couleur est représentée par la gravité d’accidents
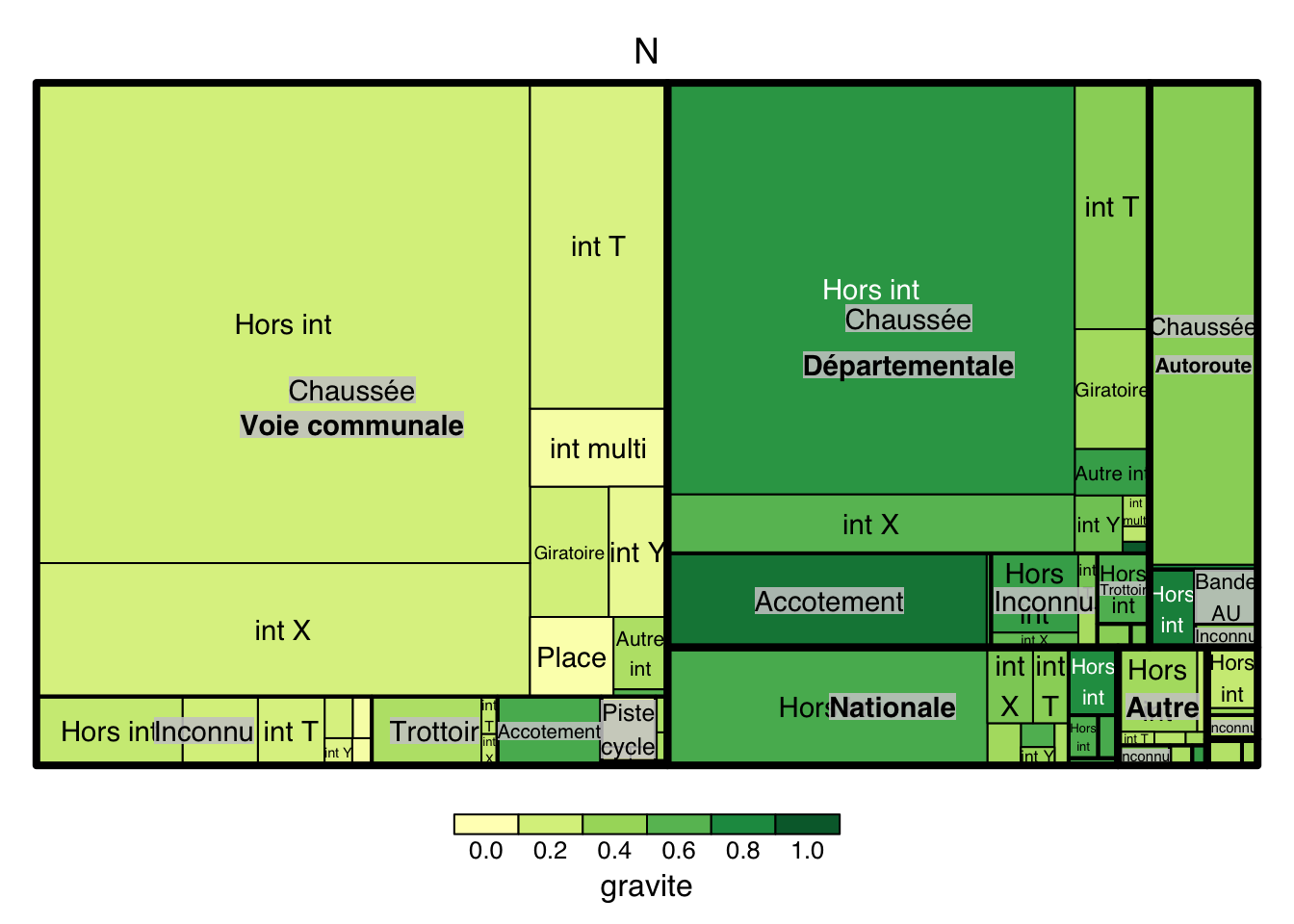
On peut remarquer que quand il y a beaucoup de variables, les petites catégories deviennent difficilement visiblement, ainsi, on peut supprimer certaines petites catégories (ou les regrouper).
5.3 Treemap interactif
Dans le treemap suivant, on peut alors visualiser les proportions de manière globale, et plus détaillée en zoomant.
6 Graphiques à pictogramme
- Pour des présentations ludiques, on peut représenter les données avec des symboles.
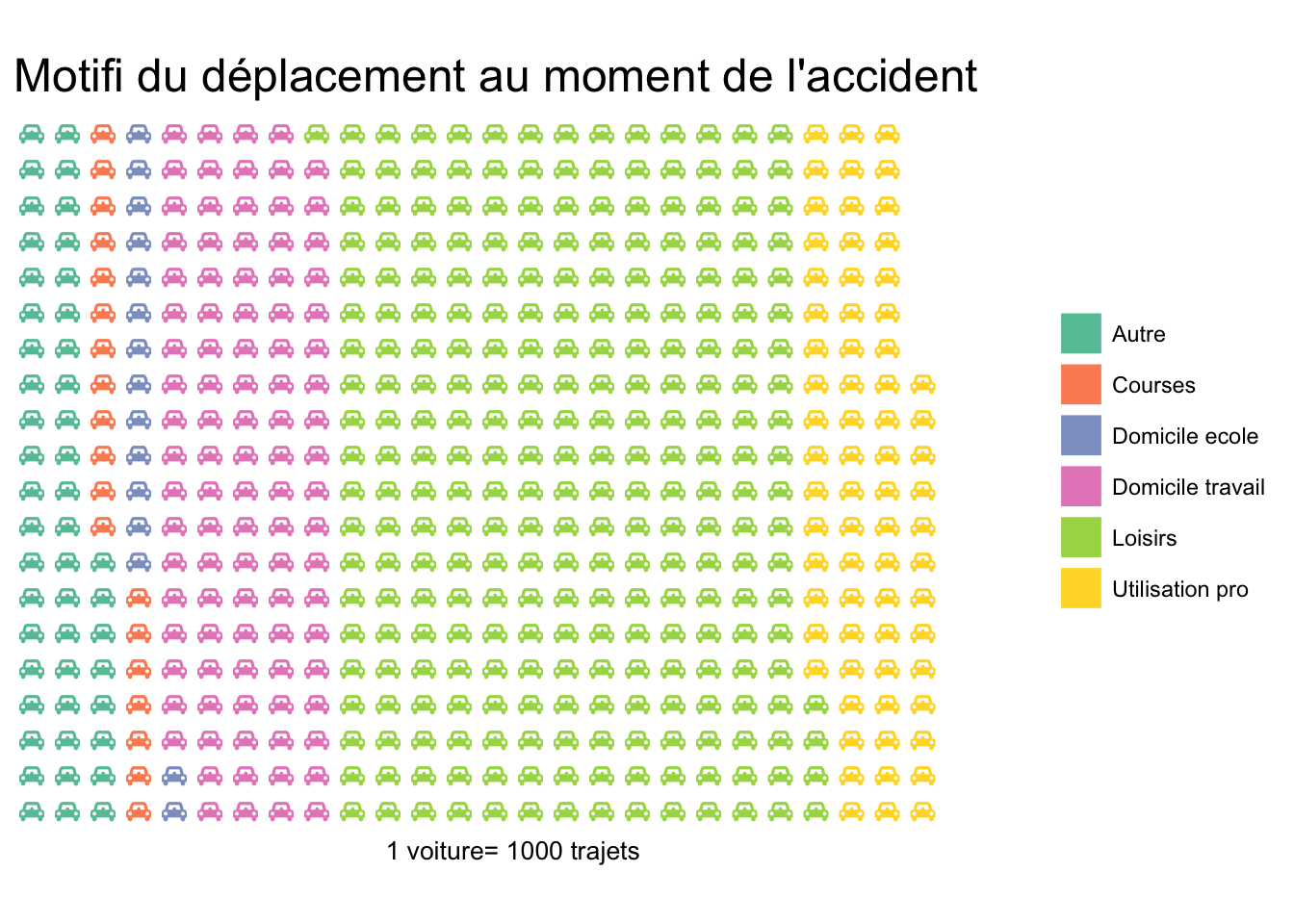
Par exemple, on peut représenter la proportion des types de trajets grâce à des pictogrammes en forme de voiture:
- Chaque voiture de couleur différente représente un type de trajet.
- Chaque voiture ici représente 1000 trajets.
- Ainsi, on peut voir de façon visuelle les différentes proportions.
- Au niveau des données, on peut remarquer qu’une petite série de nombre (6 en l’occurrence) est représentée. Mais grâce à des symboles ludiques, ces nombres simples prennent vie: le type de trajet le plus fréquent est loisirs. Ensuite, on retrouve domicile-travail et utilisation professionnelle.
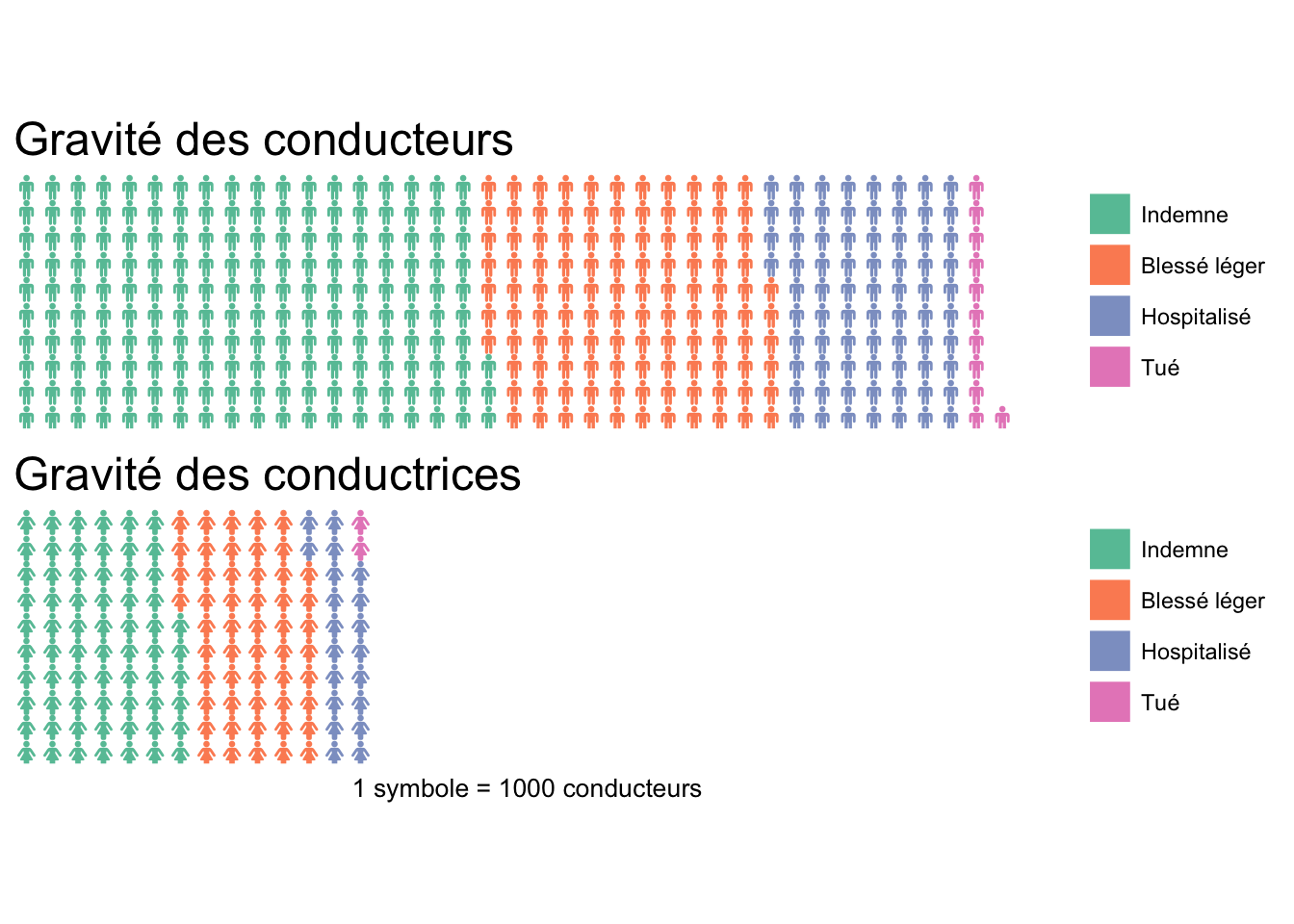
On peut également représenter le nombre d’accidents en fonction des niveaux de gravité des accidents et en fonction du sexe du conducteur.
- Chaque pictogramme, homme ou femme, représente 1000 personnes.
- Ainsi on voit à travers chaque symbole, 1000 personnes blessées à différents niveaux de gravité, ce qui est plus parlant, et alertant qu’un simple barplot.
7 Boucle d’exploration
Comme on a un certain nombre de variables dans la base, afin de mieux connaître, on peut créer une boucle pour afficher le même type de graphique.
Copyright © 2017 Blog de Kezhan Shi