Classification
Informations
1 Introduction
2 Abre de décision
2.1 Introduction
On va le processus de machine learning complet avec un arbre de décision.
2.2 Tâche
Dans un permier temps, on doit définir la tâche de classification:
- Type de tâche: ici, il s’agit d’une classification
- Données
- Variable cible
- classe positive à préciser si nécessaire
2.3 Algorithme
On va utiliser l’arbre de décision dans un premier temps, et on verra les autres algorithmes ultérieurement. On doit aussi préciser la base d’apprentissage et la base de test.
2.4 Apprentissage du modèle
On peut maintenant créer un modèle de prédiction, avec les données d’apprentissage. On doit préciser les éléments suivants qui ont été définis précédémment:
- la tâche,
- l’algorithme
- la base d’apprentissage
2.5 Prédiction
On peut maintenant prédire des résultats sur la base de test, ainsi, on doit préciser les éléments suivants:
- la tâche
- le modèle
- la base de test
2.6 Validation
On évalue la performance de la prédiction. Comme c’est une classification, on peut voir la matrice de confusion.
## predicted
## true No Yes -err.-
## No 1555 166 166
## Yes 333 294 333
## -err.- 333 166 499On peut également obtenir d’autres éléments de performance comme le taux de précision. On verra d’autres mesures par suite.
## acc
## 0.78747873 Comparaison des algorithmes
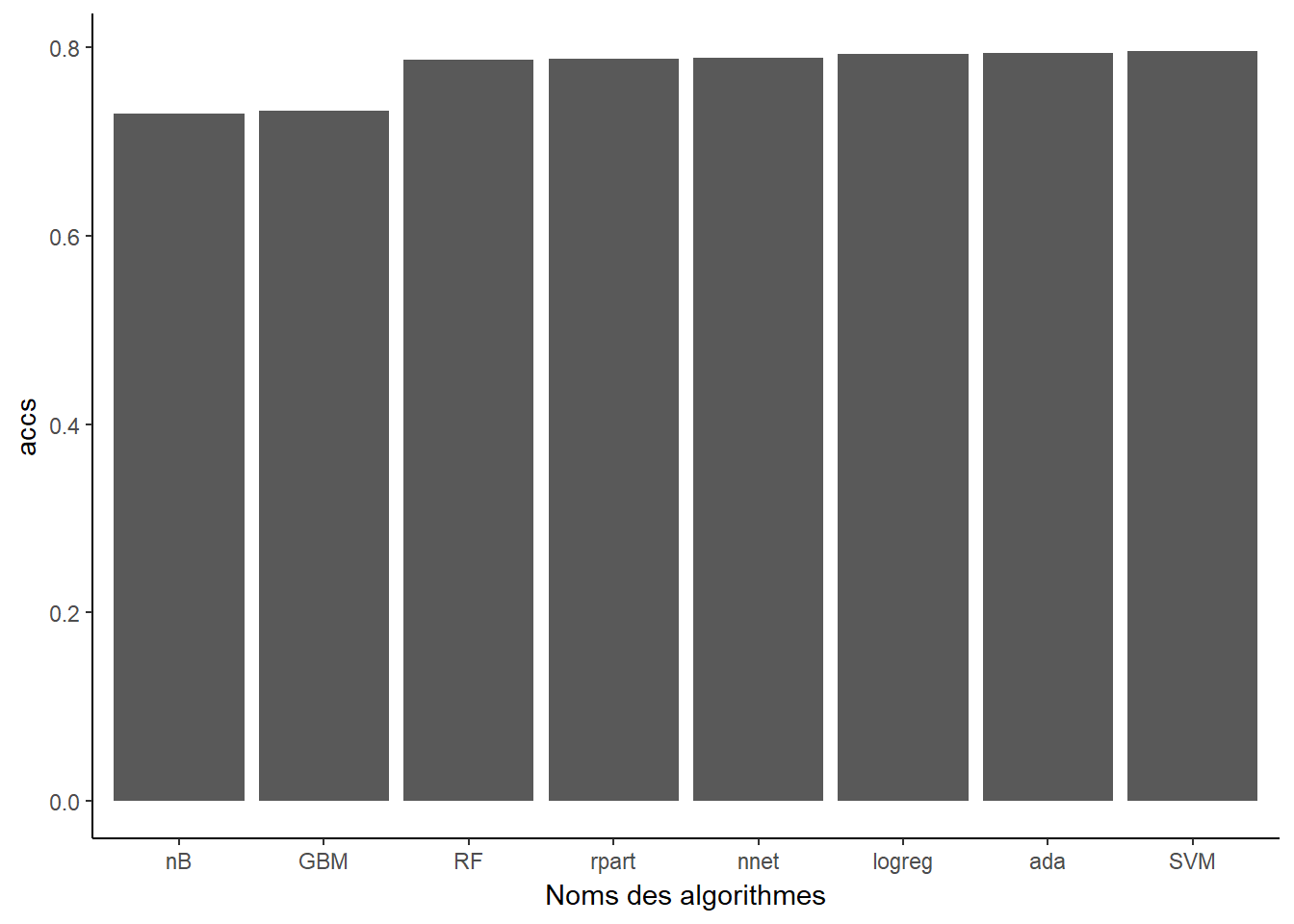
3.1 Algorithmes de classification
3.2 Comparaison performance
## # weights: 97
## initial value 2724.872852
## iter 10 value 2689.101826
## iter 20 value 2456.206010
## iter 30 value 2404.224637
## iter 40 value 2282.191251
## iter 50 value 2216.915890
## iter 60 value 2038.355409
## iter 70 value 2003.589900
## iter 80 value 1996.909234
## iter 90 value 1993.940926
## iter 100 value 1984.536877
## final value 1984.536877
## stopped after 100 iterations
## Distribution not specified, assuming bernoulli ...