Exploration des données
Informations
Il s’agit d’un extrait de la formation. Cette formation peut se faire en présentiel ou à distance. Pour en savoir plus, merci de me contacter.
1 Introduction
L’objectif est de construire un programme pour explorer automatiquement les bases de données, en donnant les principales caractéristiques des données.
Le programme est construit pour explorer automatiquement une base de données.
On considère qu’on a la classe des observations.
2 Structure des données
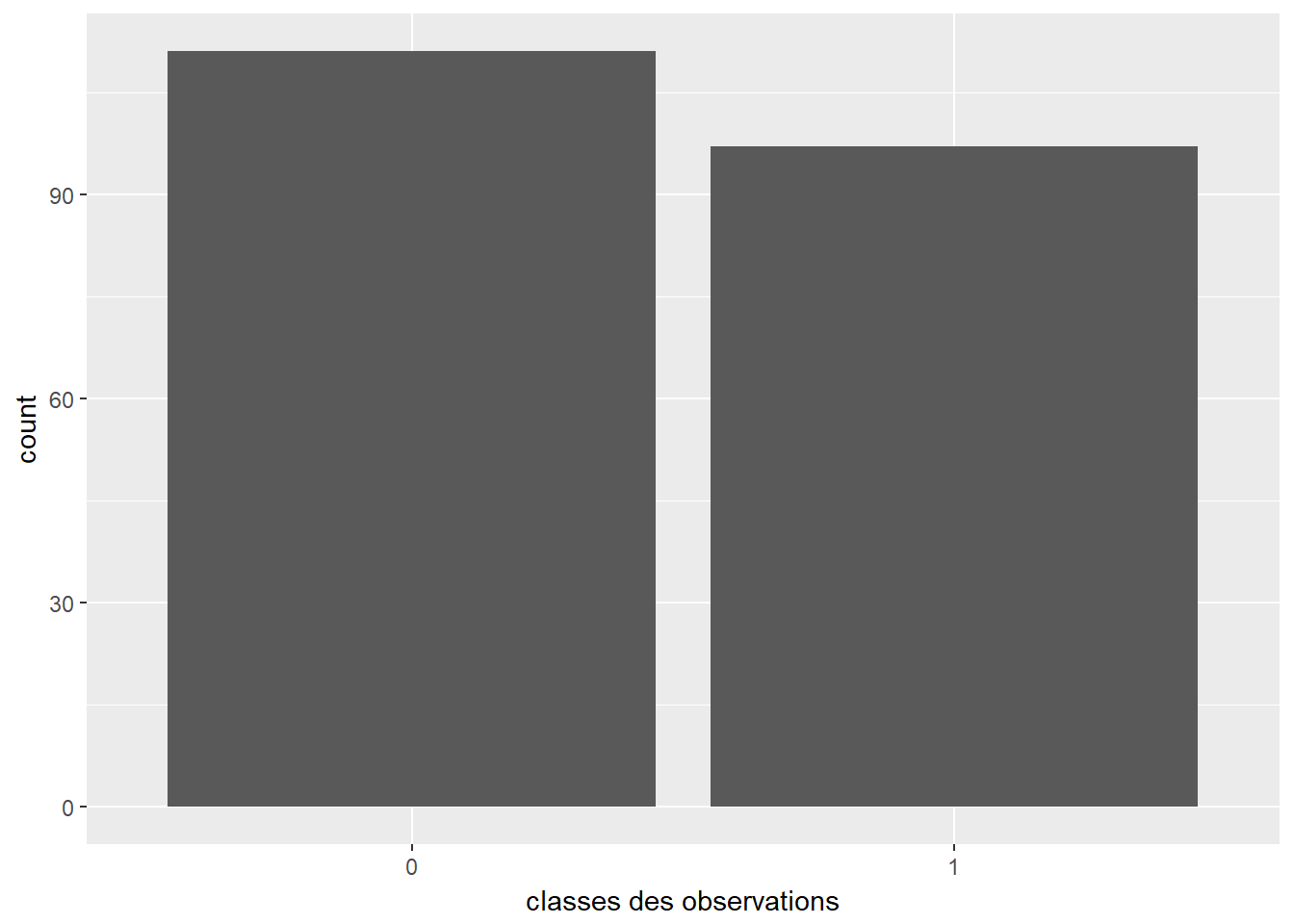
2.1 Classes d’observation
2.2 Histogrammes
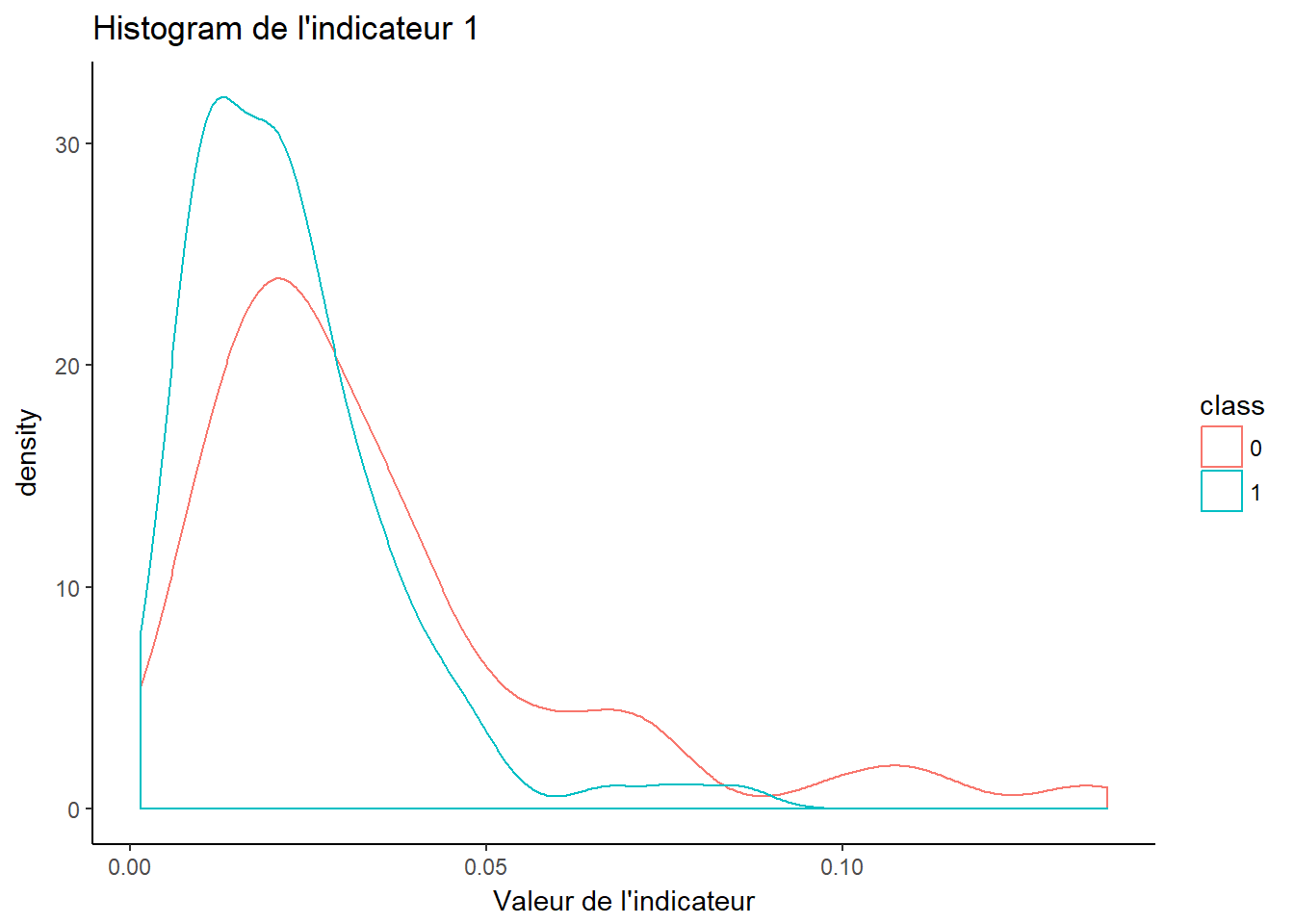
2.2.1 Indicateur 1
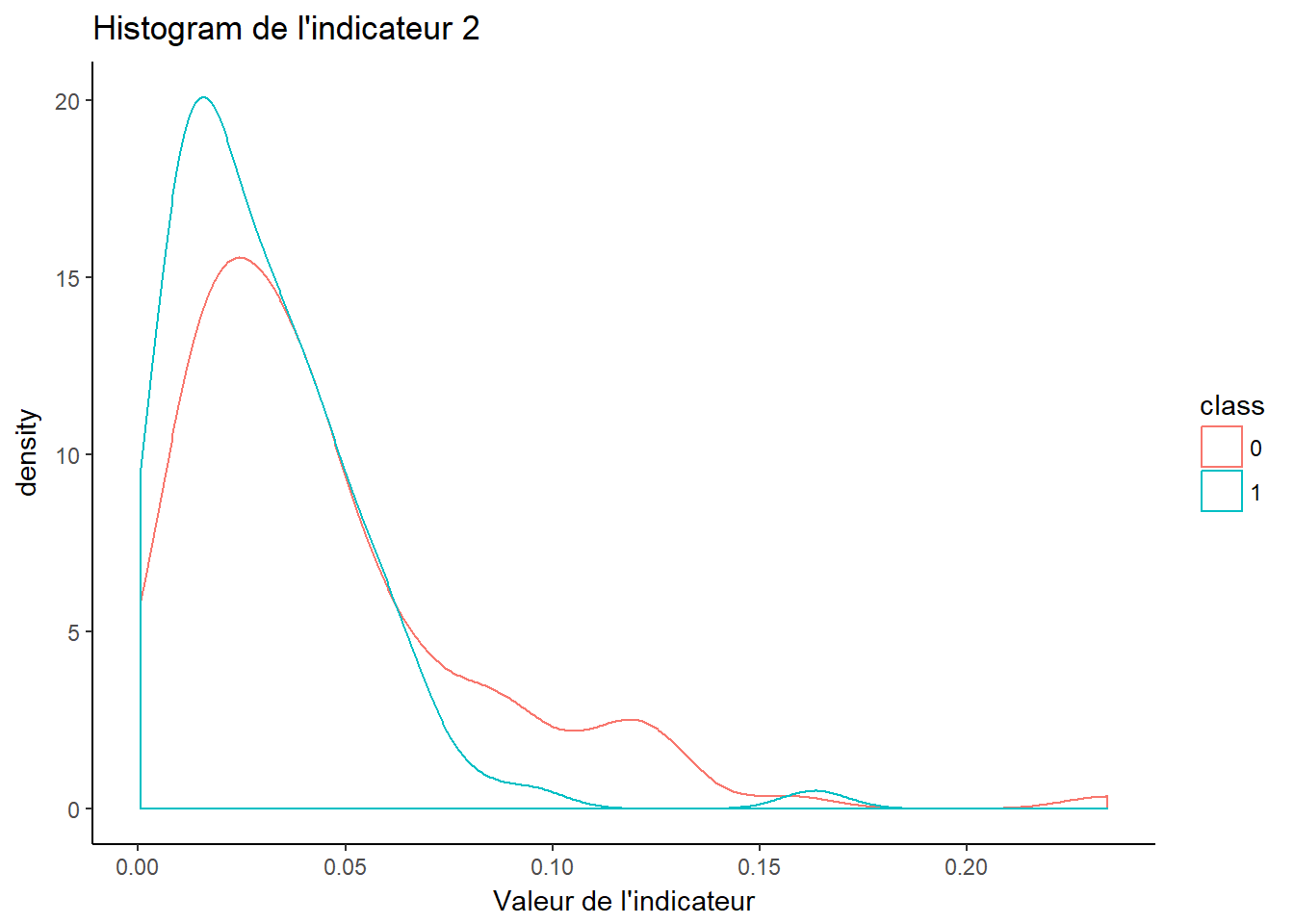
2.2.2 Indicateur 2
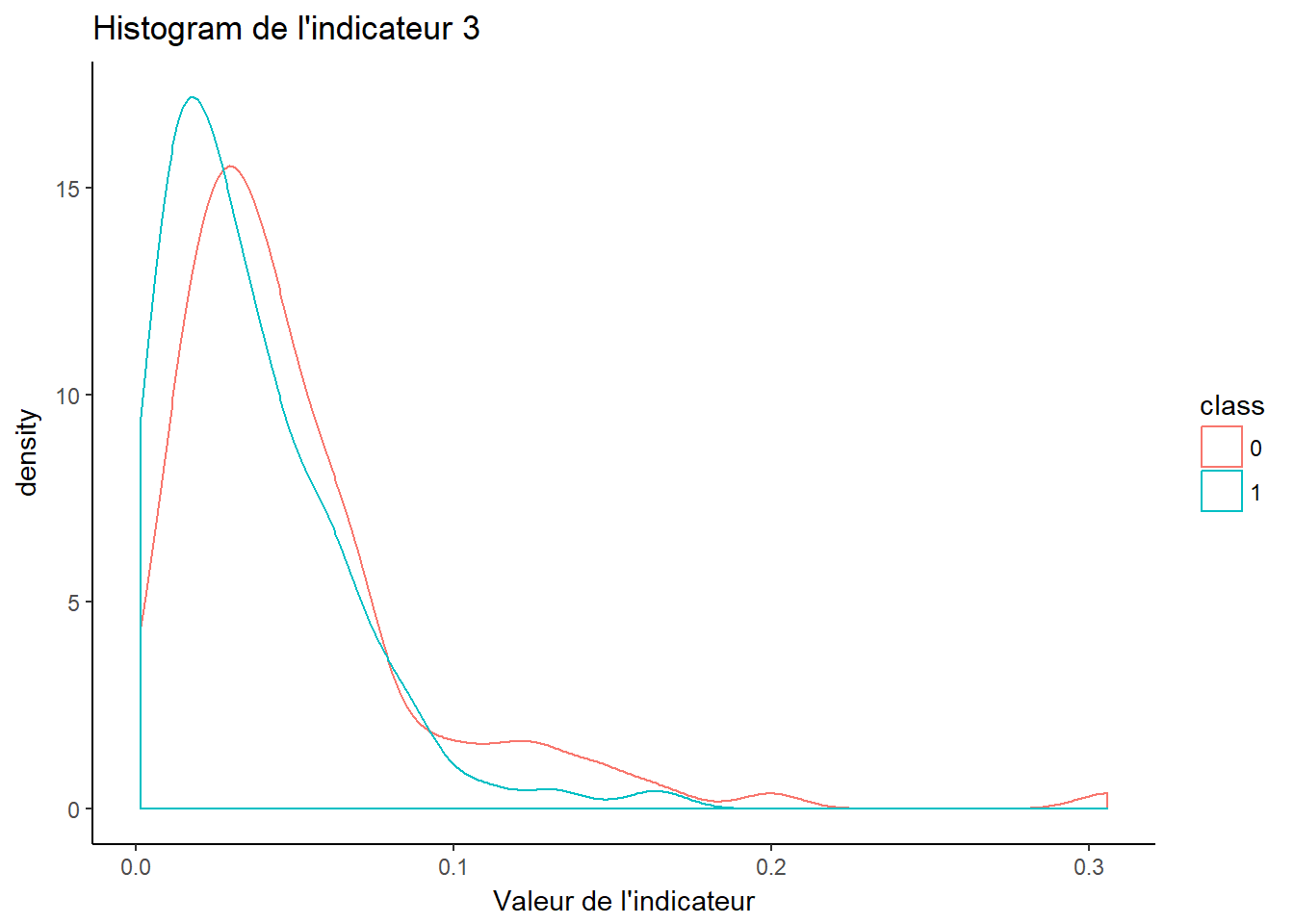
2.2.3 Indicateur 3
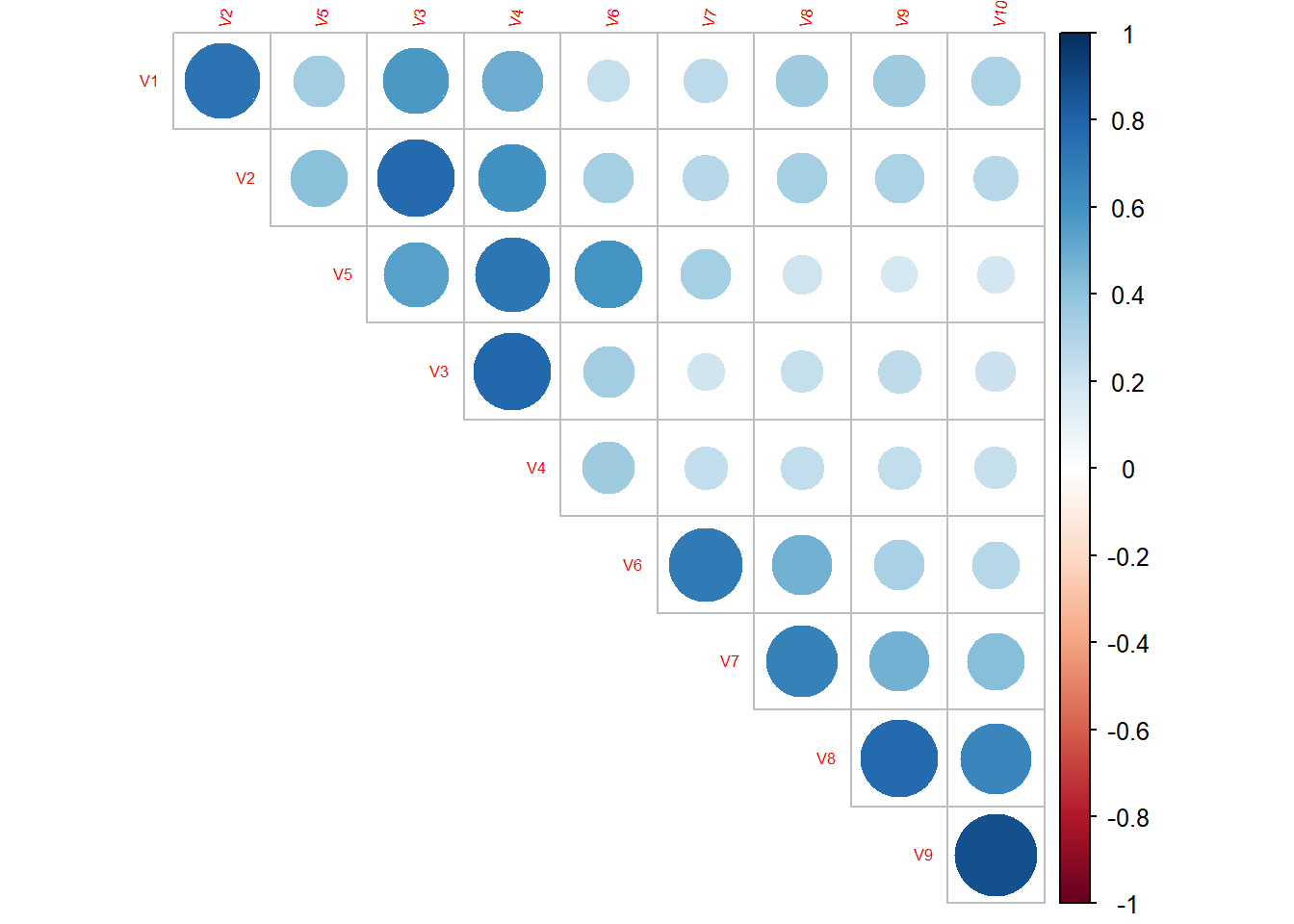
2.3 Corrélation
2.3.1 Toutes les classes
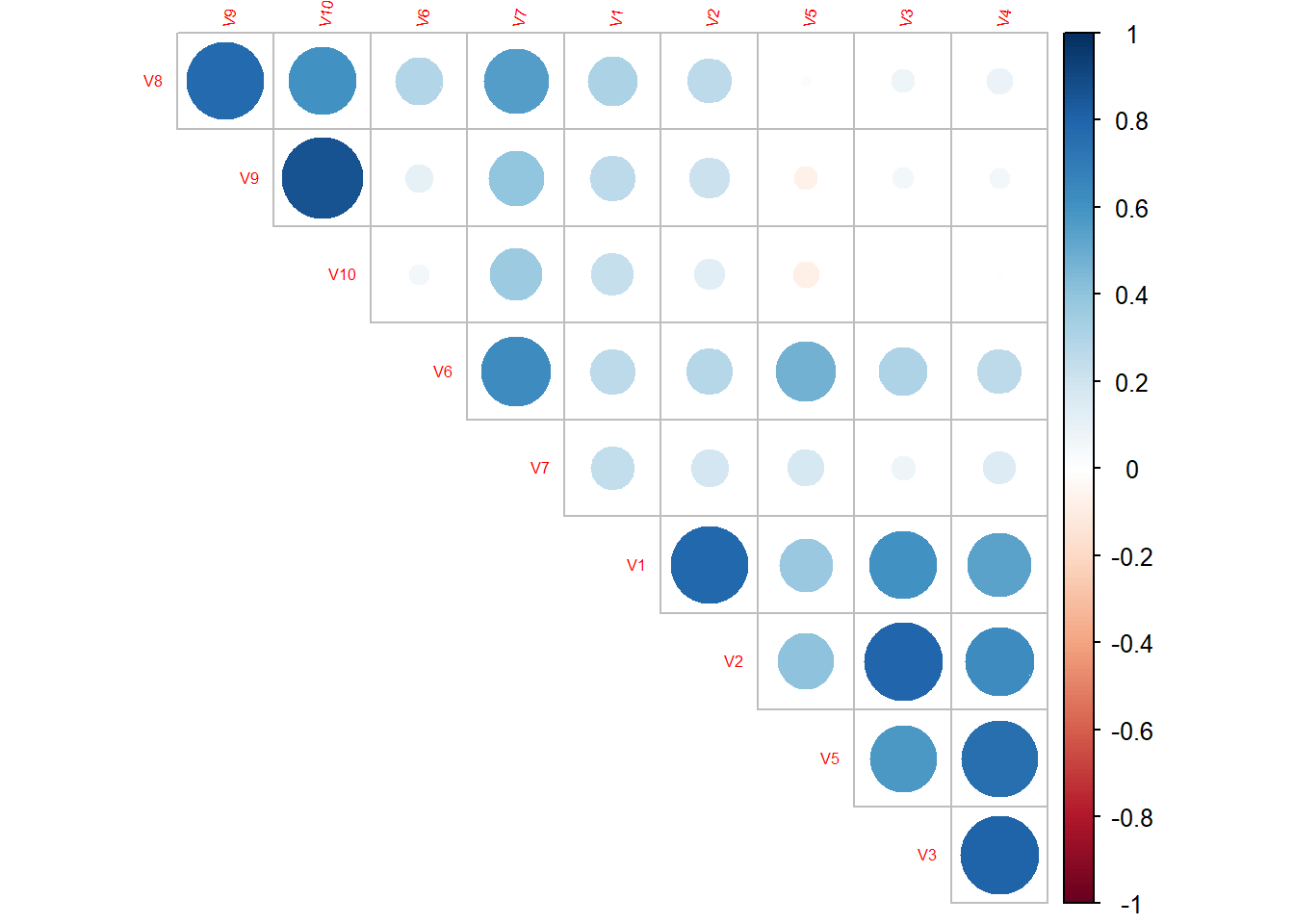
2.3.2 Classe 0
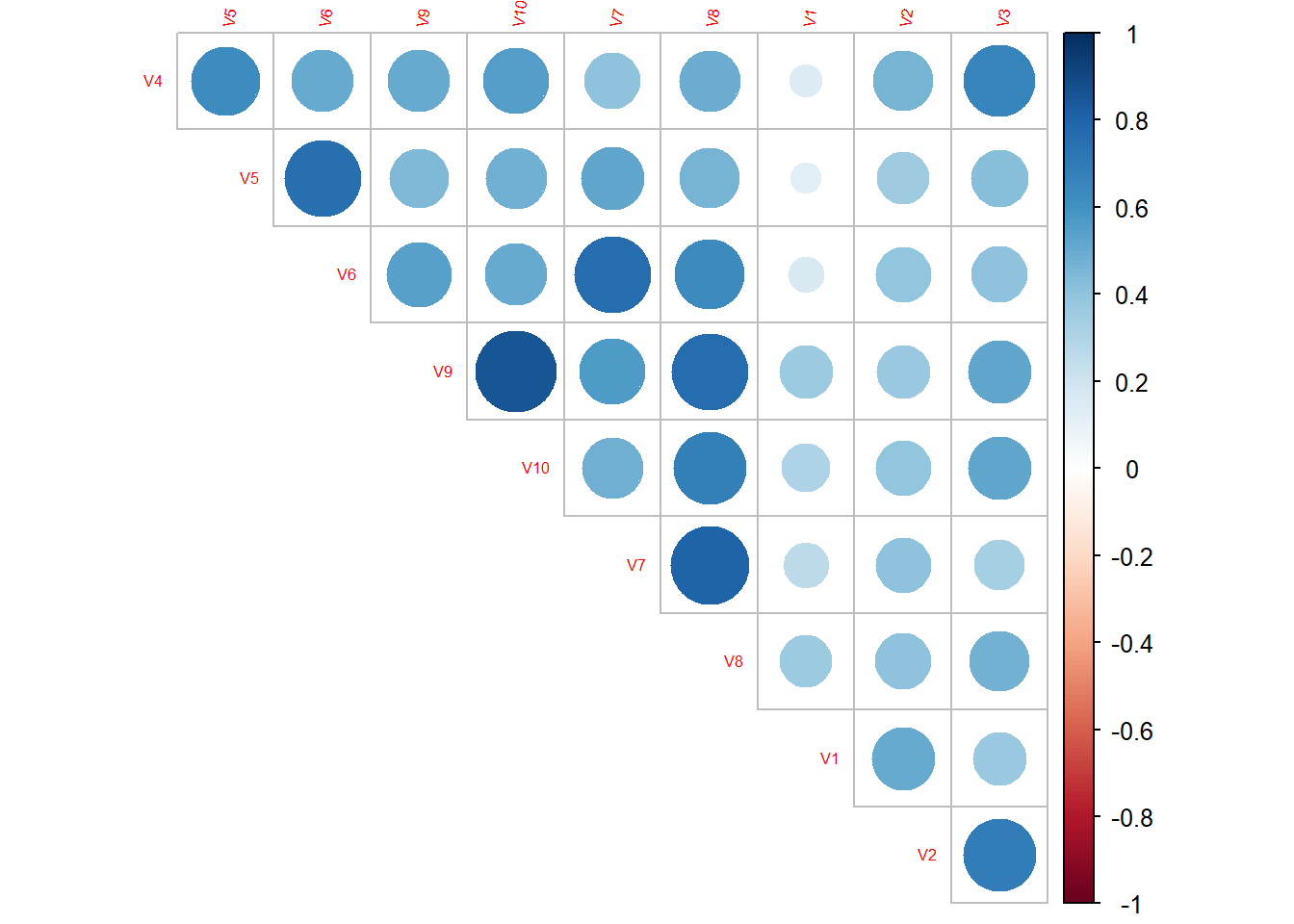
2.3.3 Classe 1
2.4 Relations 2 variables
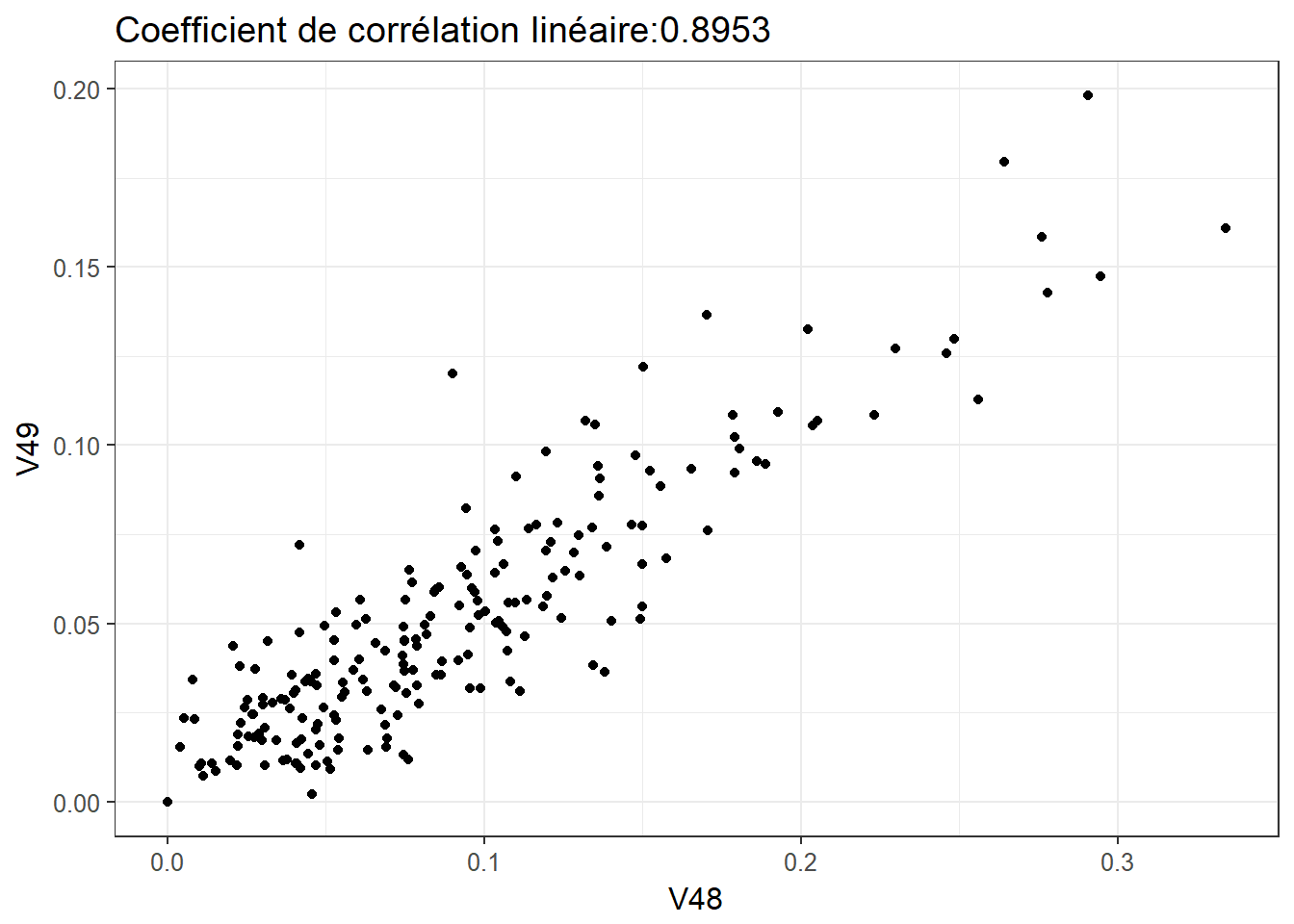
2.4.1 Relation 1
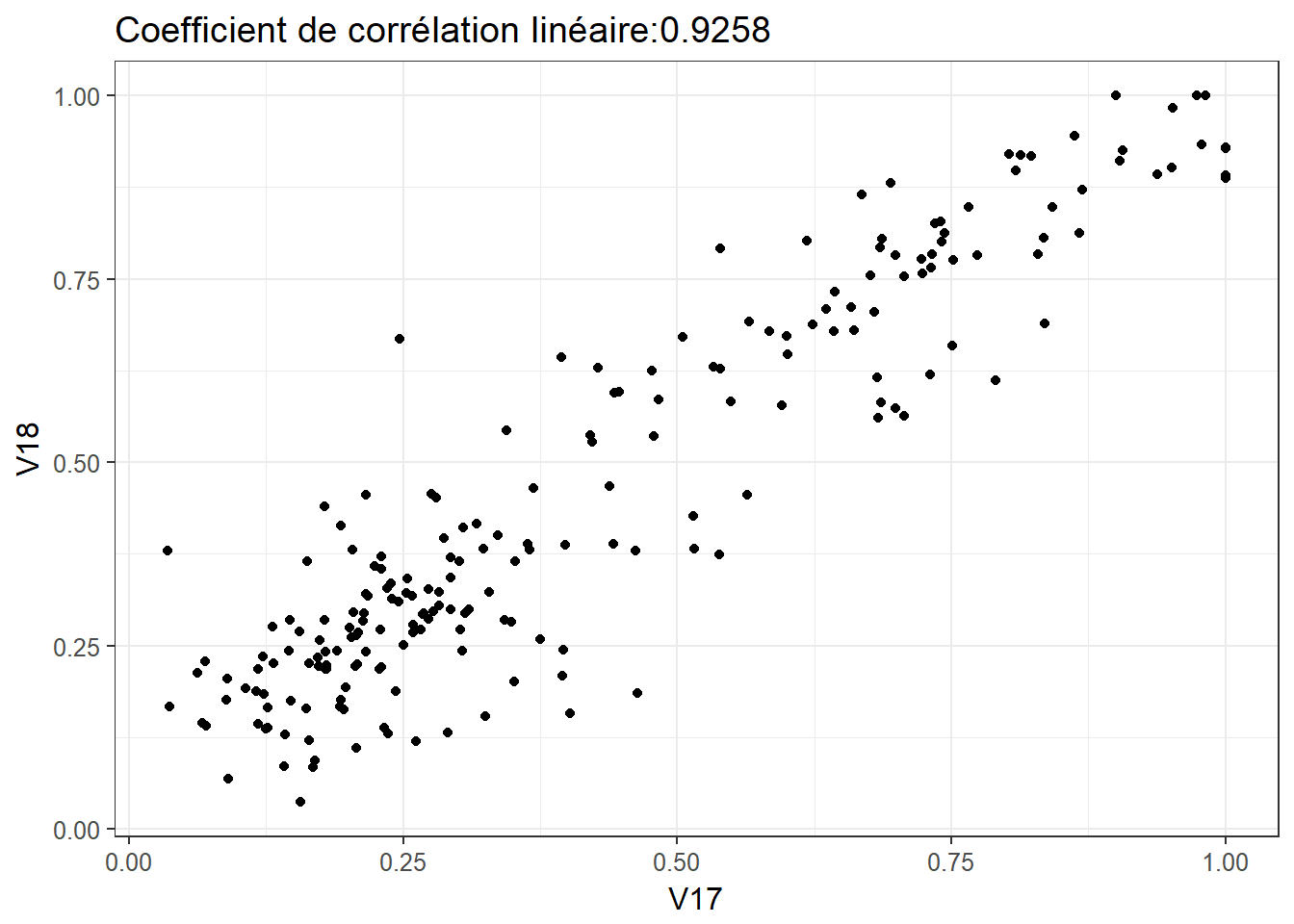
2.4.2 Relation 2
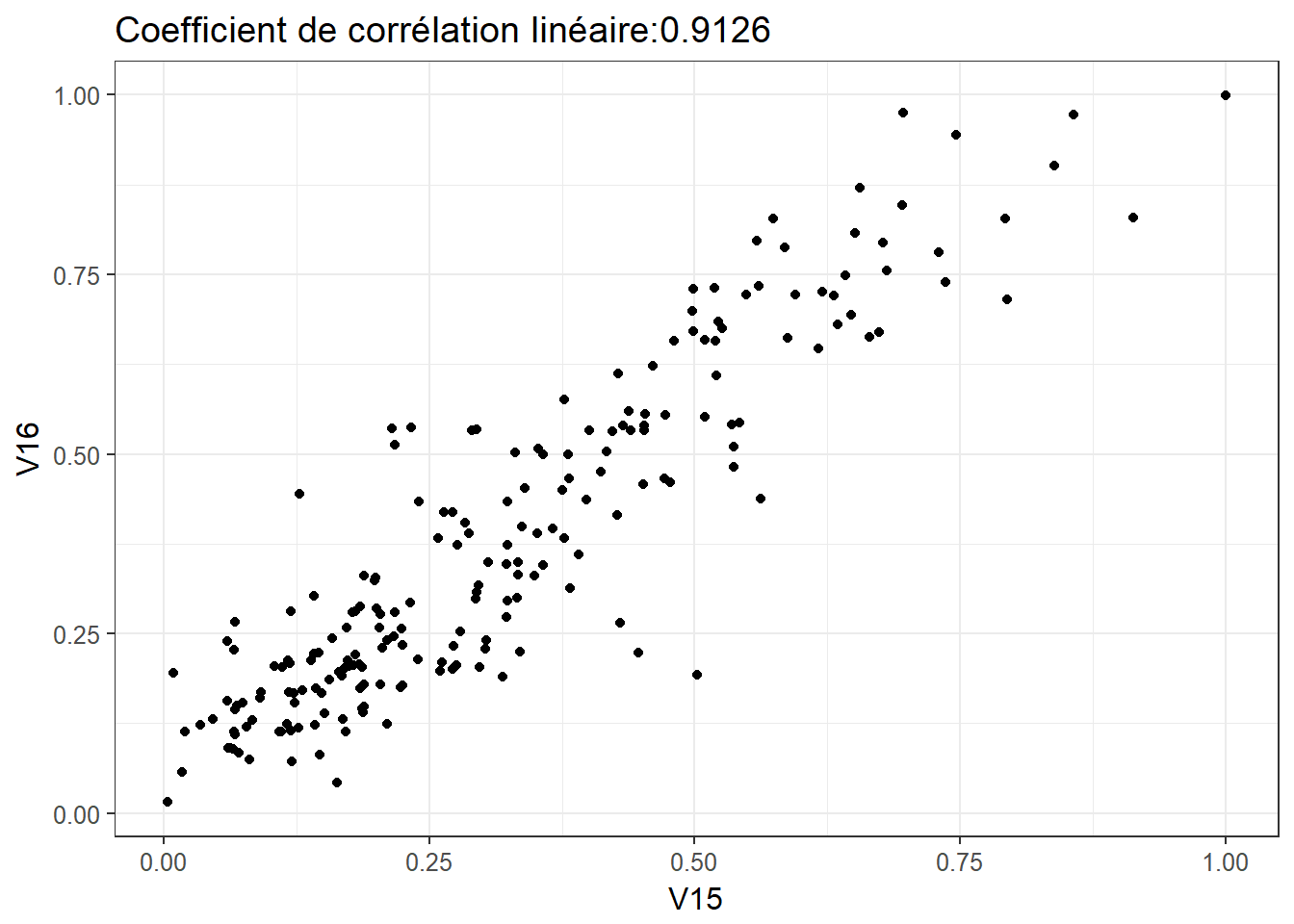
2.4.3 Relation 3
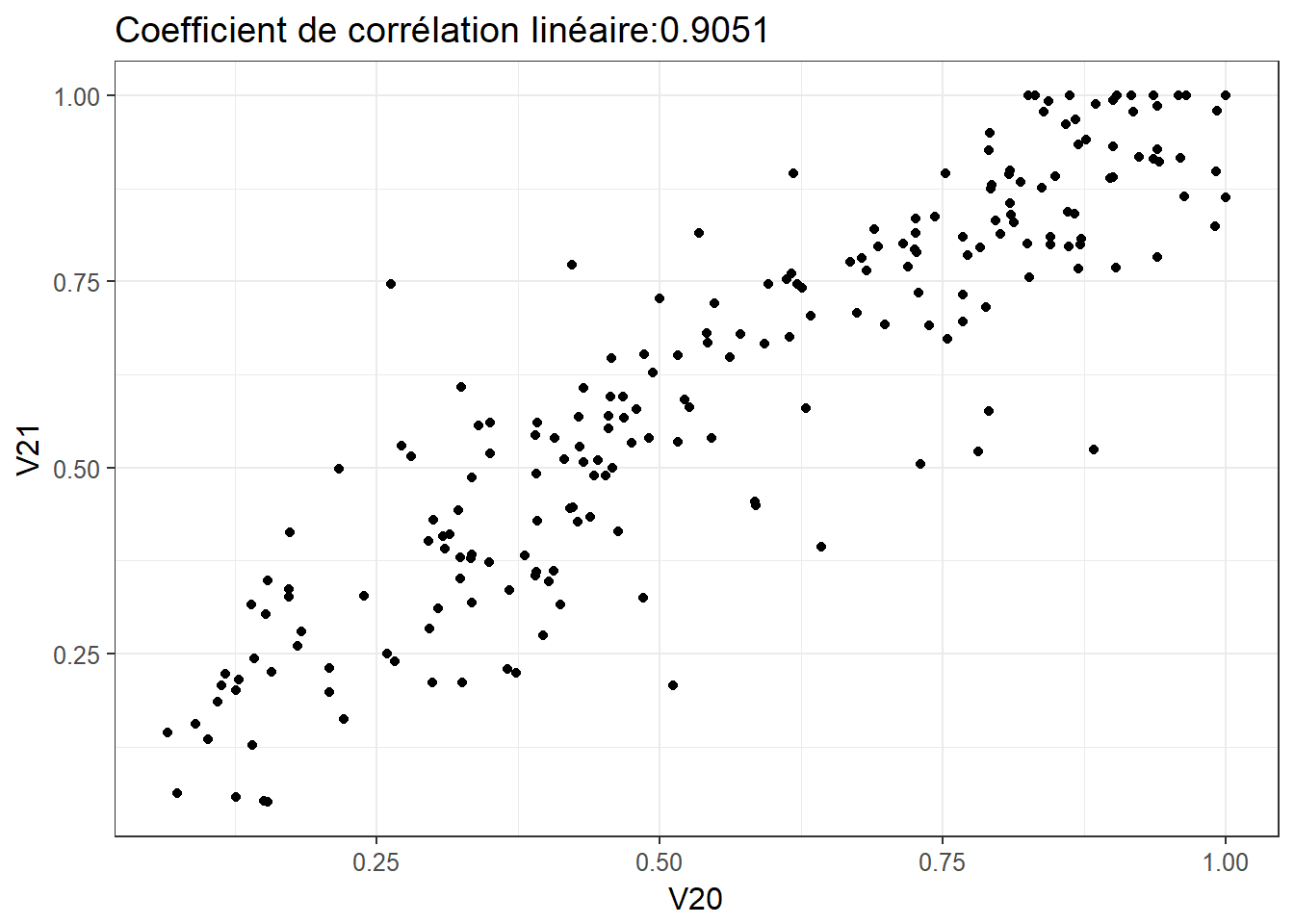
2.4.4 Relation 4
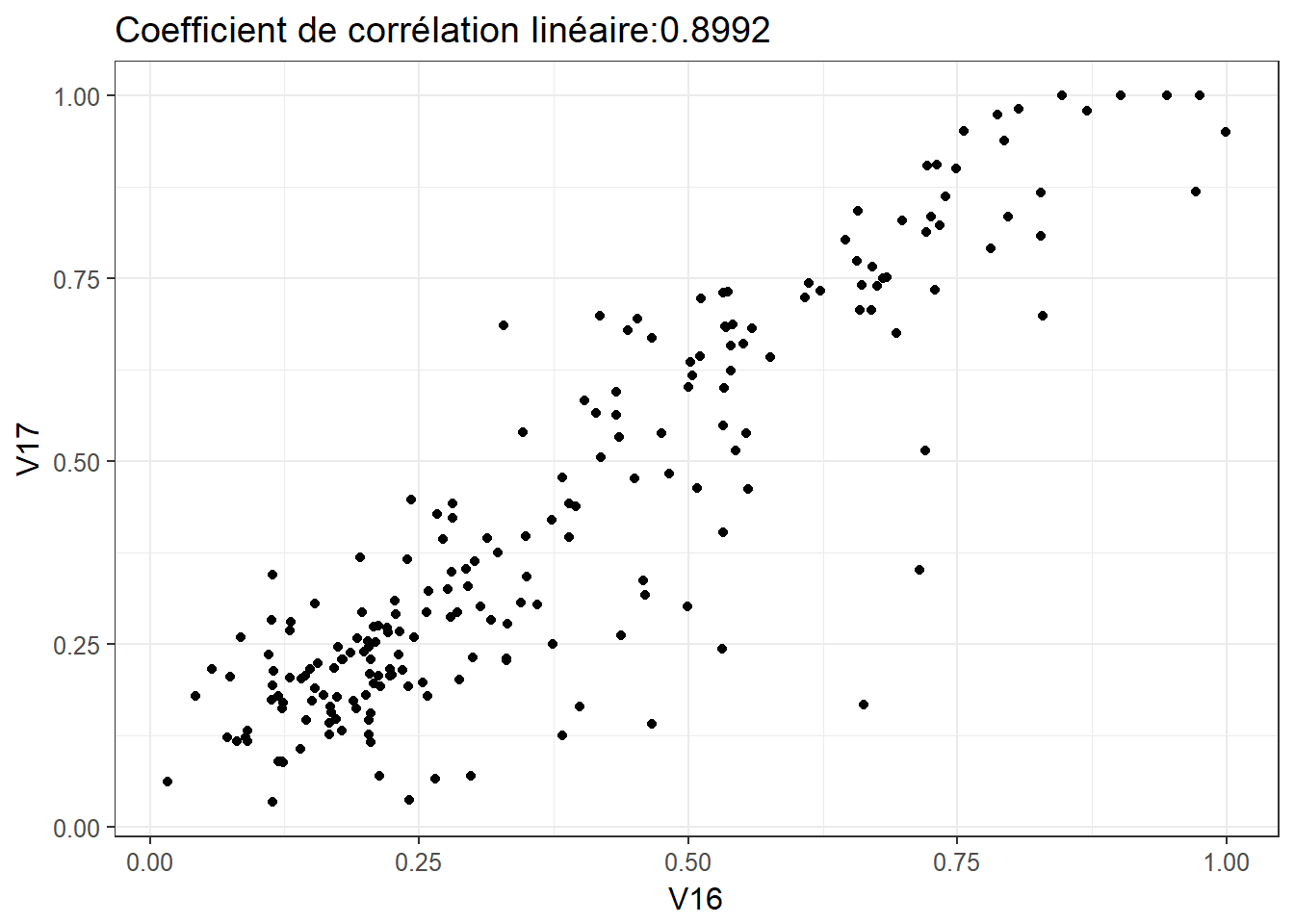
2.4.5 Relation 5
3 Test de normalité
Avant de procéder à certaines transformations des données, on va d’abord tester la normalité des variables.
3.1 Quantiles
| 0% | 10% | 25% | 50% | 75% | 90% | 100% | |
|---|---|---|---|---|---|---|---|
| V1 | 0.0015 | 0.00937 | 0.013350 | 0.02280 | 0.035550 | 0.05471 | 0.1371 |
| V2 | 0.0006 | 0.00902 | 0.016450 | 0.03080 | 0.047950 | 0.08119 | 0.2339 |
| V3 | 0.0015 | 0.00997 | 0.018950 | 0.03430 | 0.057950 | 0.08420 | 0.3059 |
| V4 | 0.0058 | 0.01410 | 0.024375 | 0.04405 | 0.064500 | 0.10836 | 0.4264 |
| V5 | 0.0067 | 0.02164 | 0.038050 | 0.06250 | 0.100275 | 0.14006 | 0.4010 |
| V6 | 0.0102 | 0.03892 | 0.067025 | 0.09215 | 0.134125 | 0.17922 | 0.3823 |
3.2 QQplot
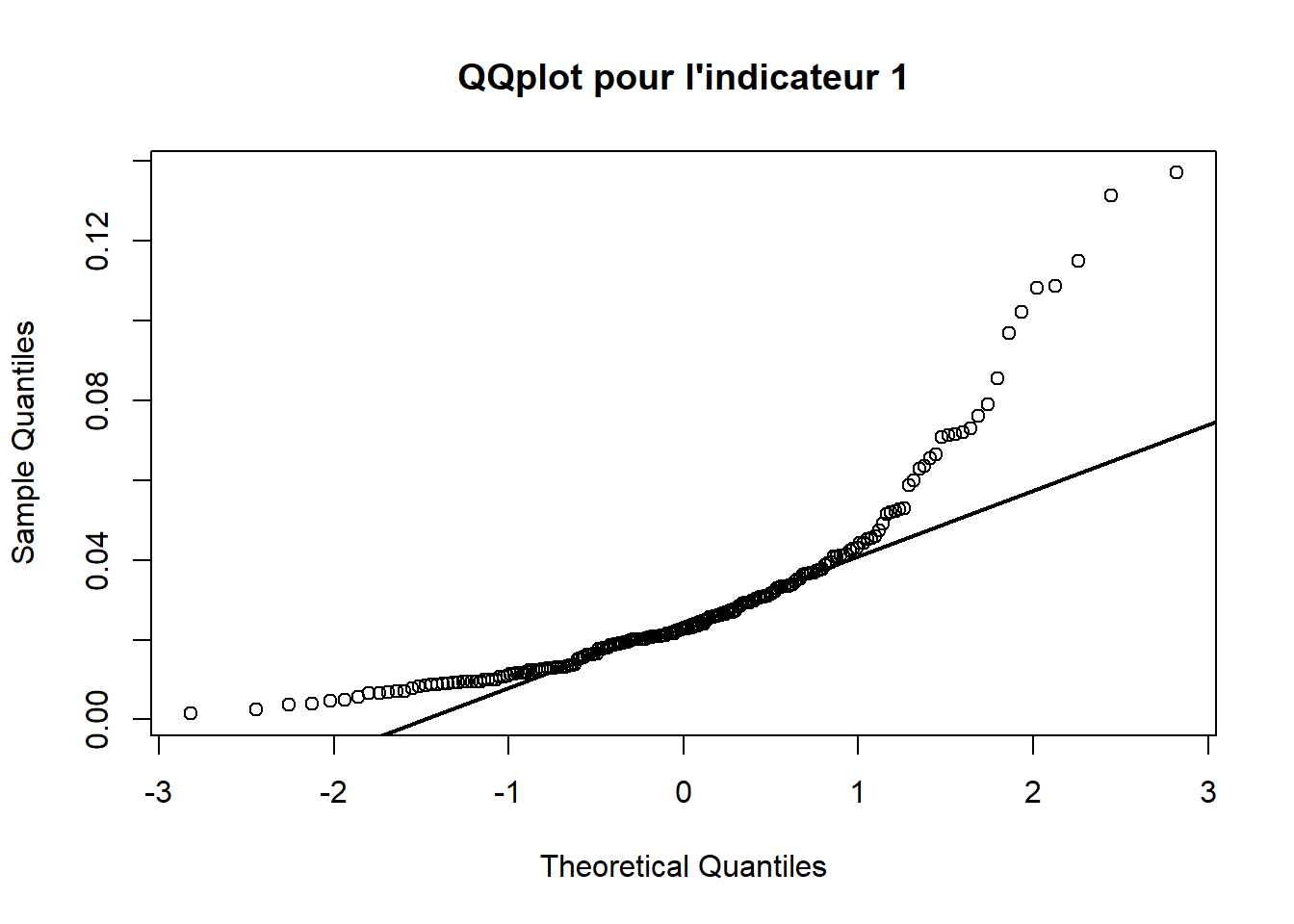
3.2.1 QQplot 1
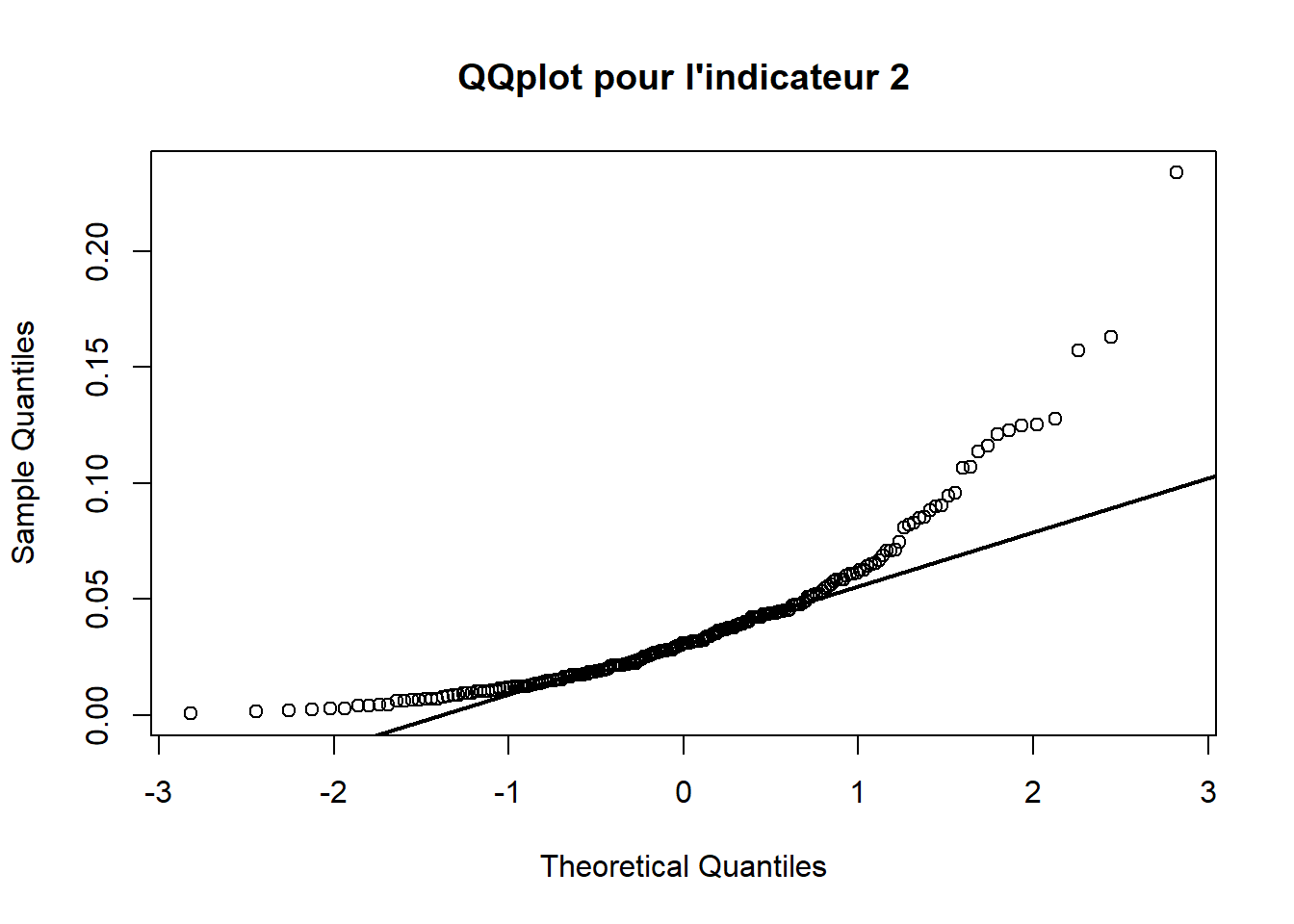
3.2.2 QQplot 2
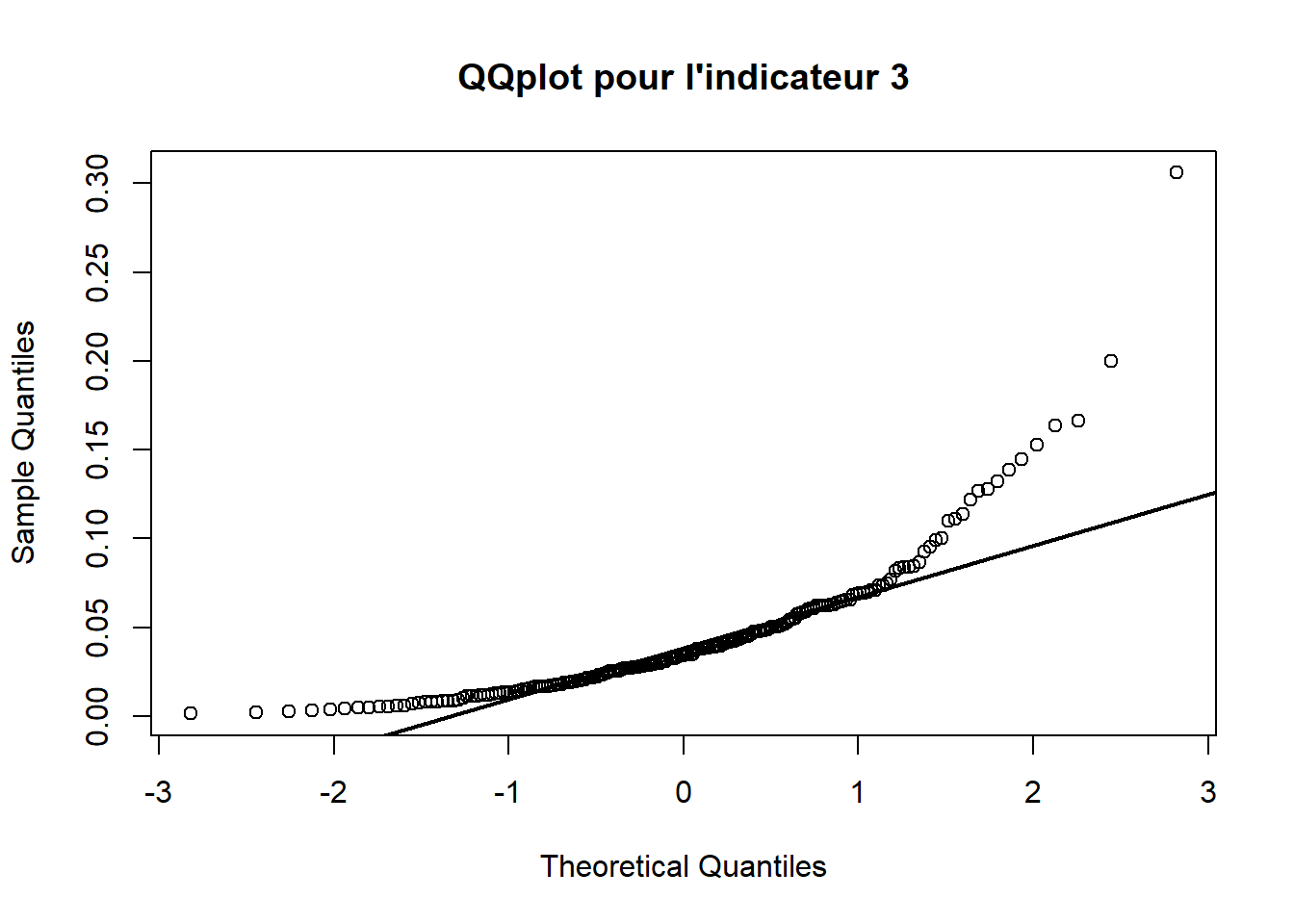
3.2.3 QQplot 3
3.2.4 QQplot 4
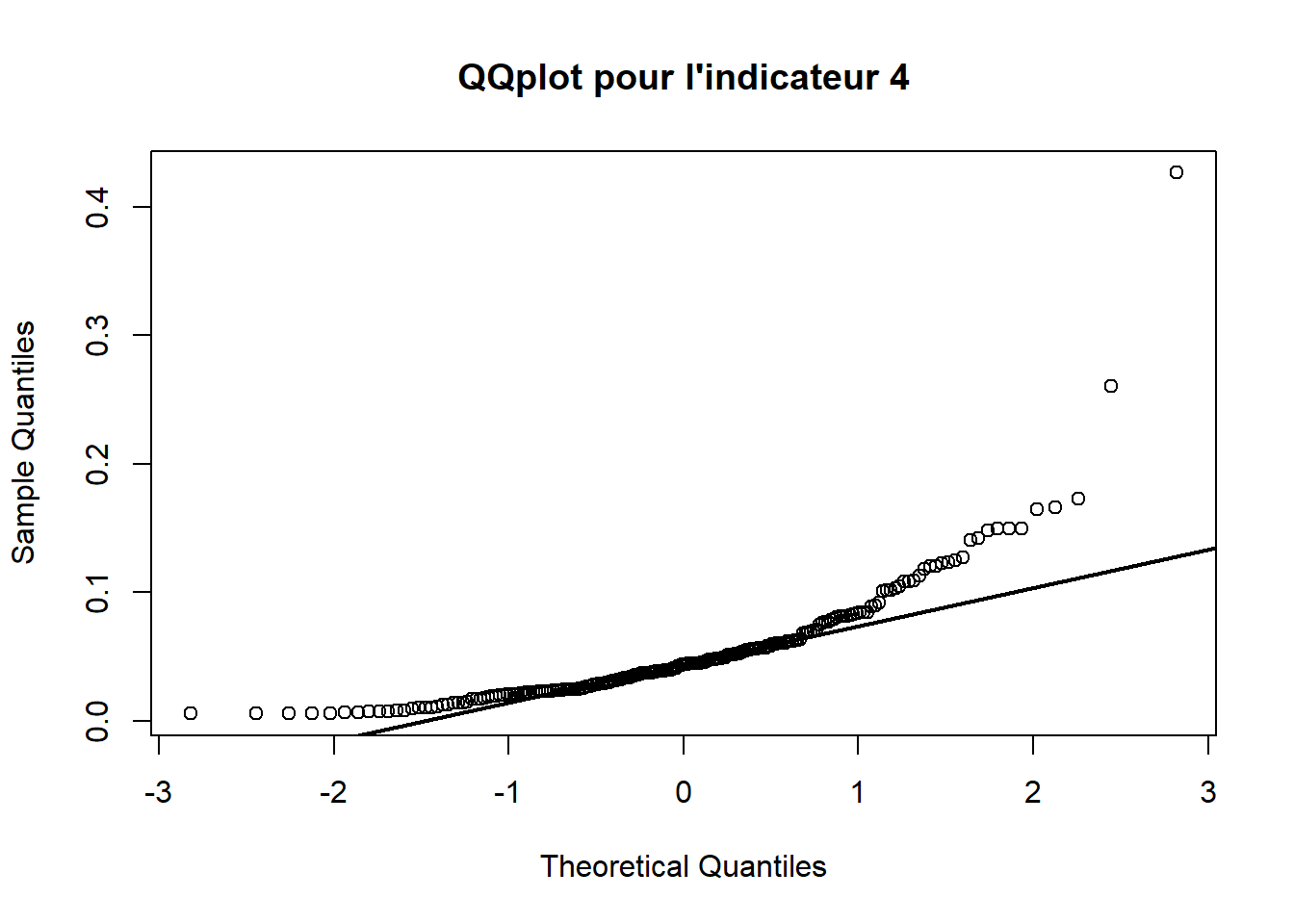
3.2.5 QQplot 5
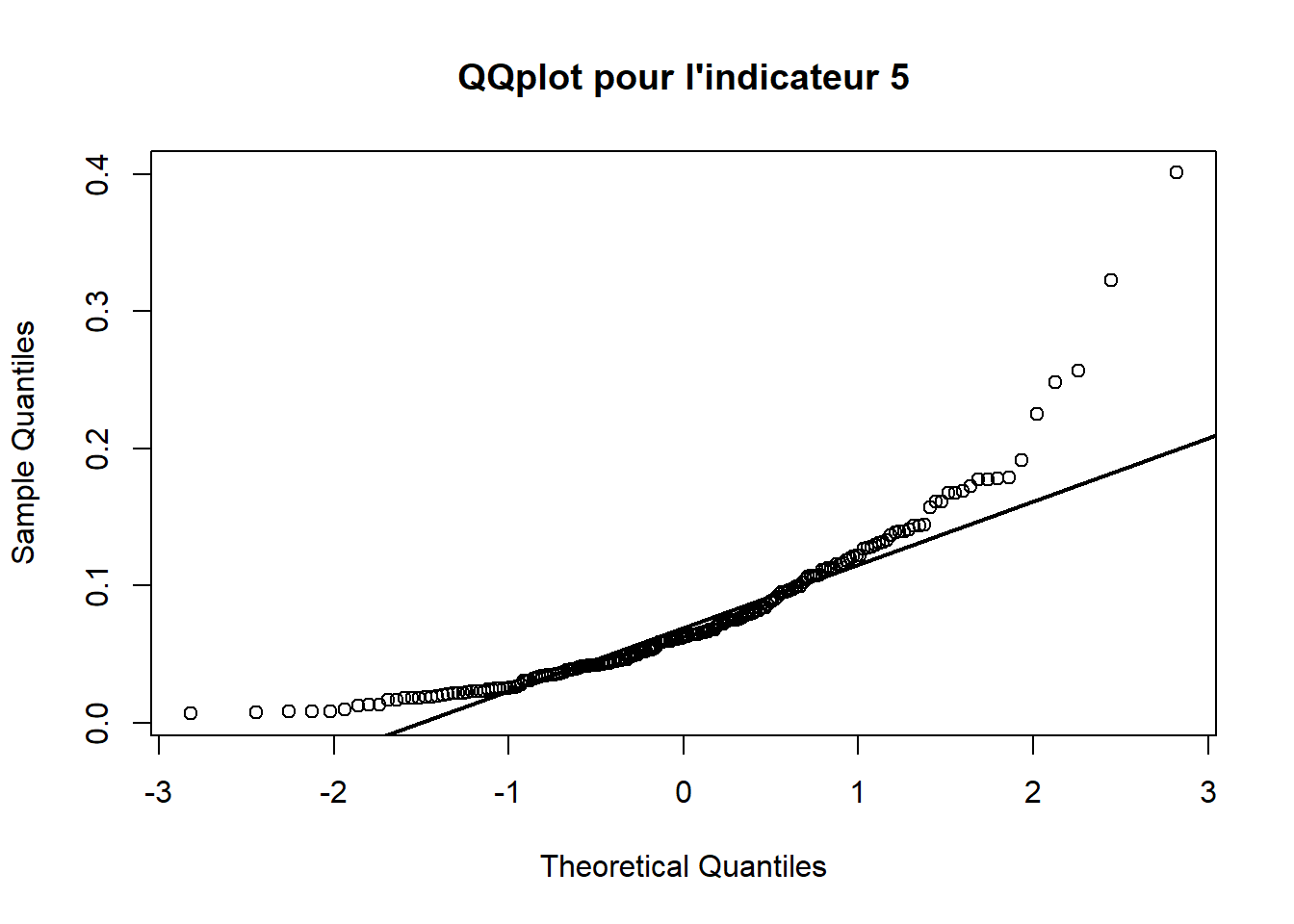
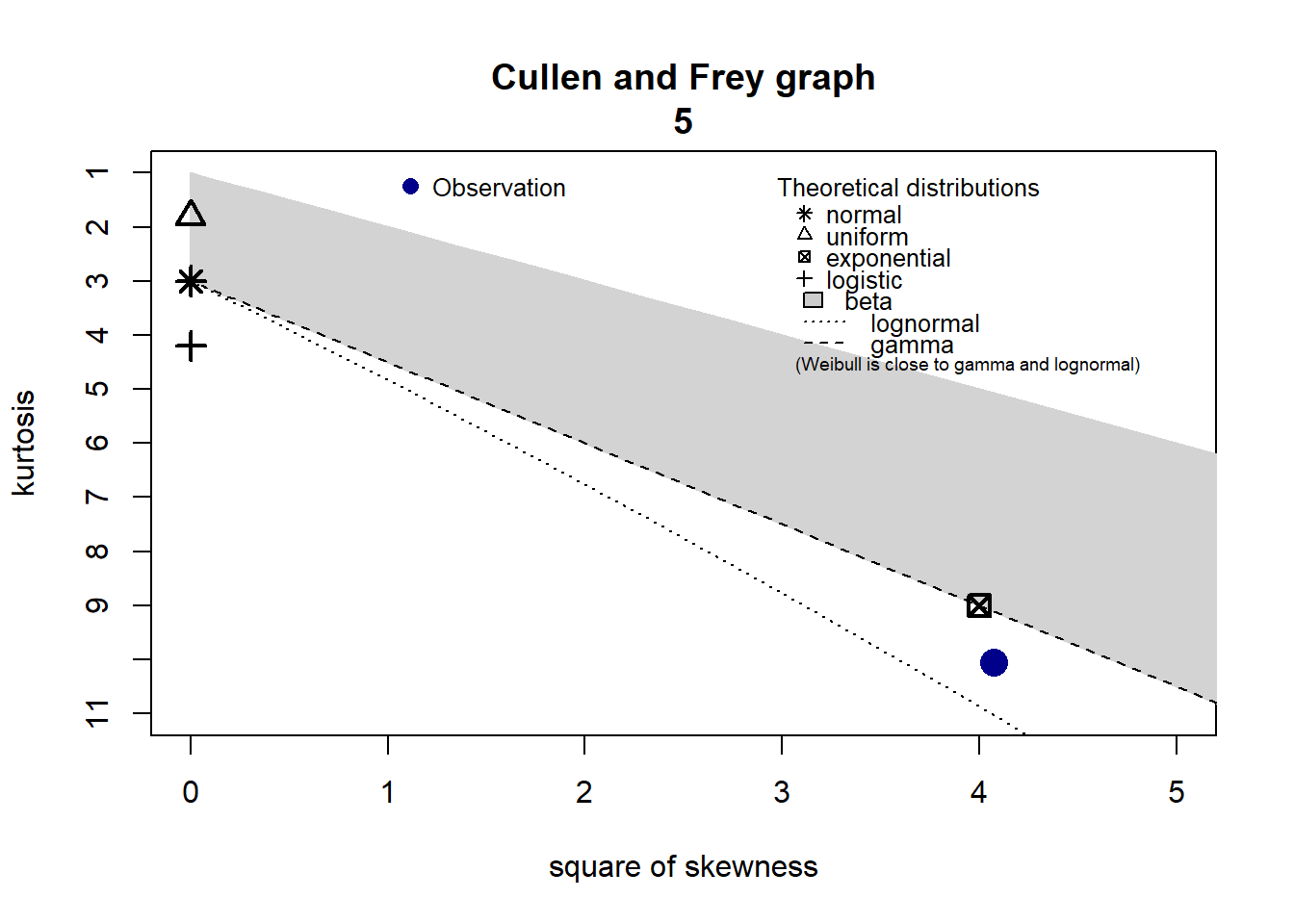
3.3 Adéquation loi
3.3.1 Adéquation loi 1
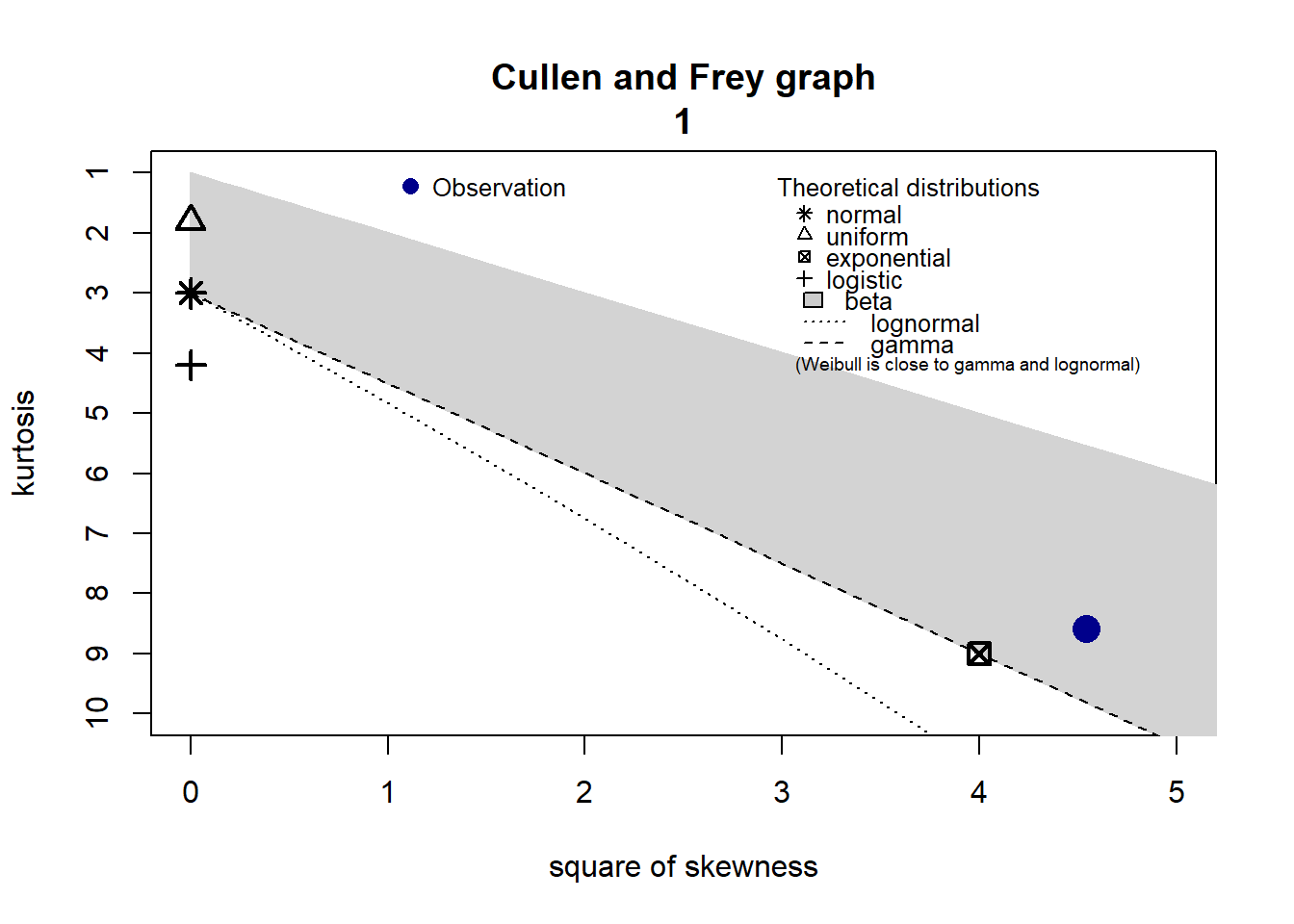
3.3.2 Adéquation loi 2
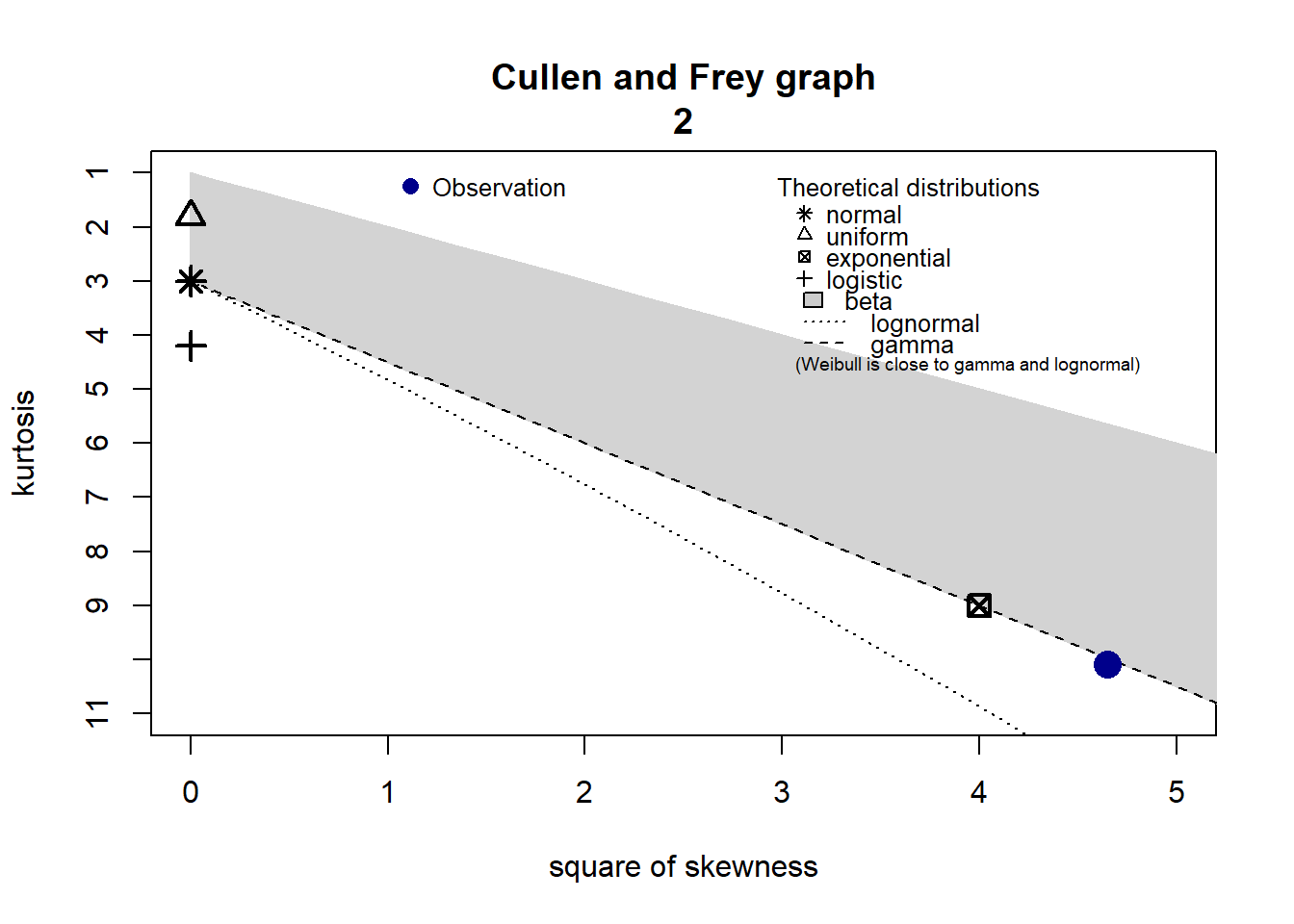
3.3.3 Adéquation loi 3
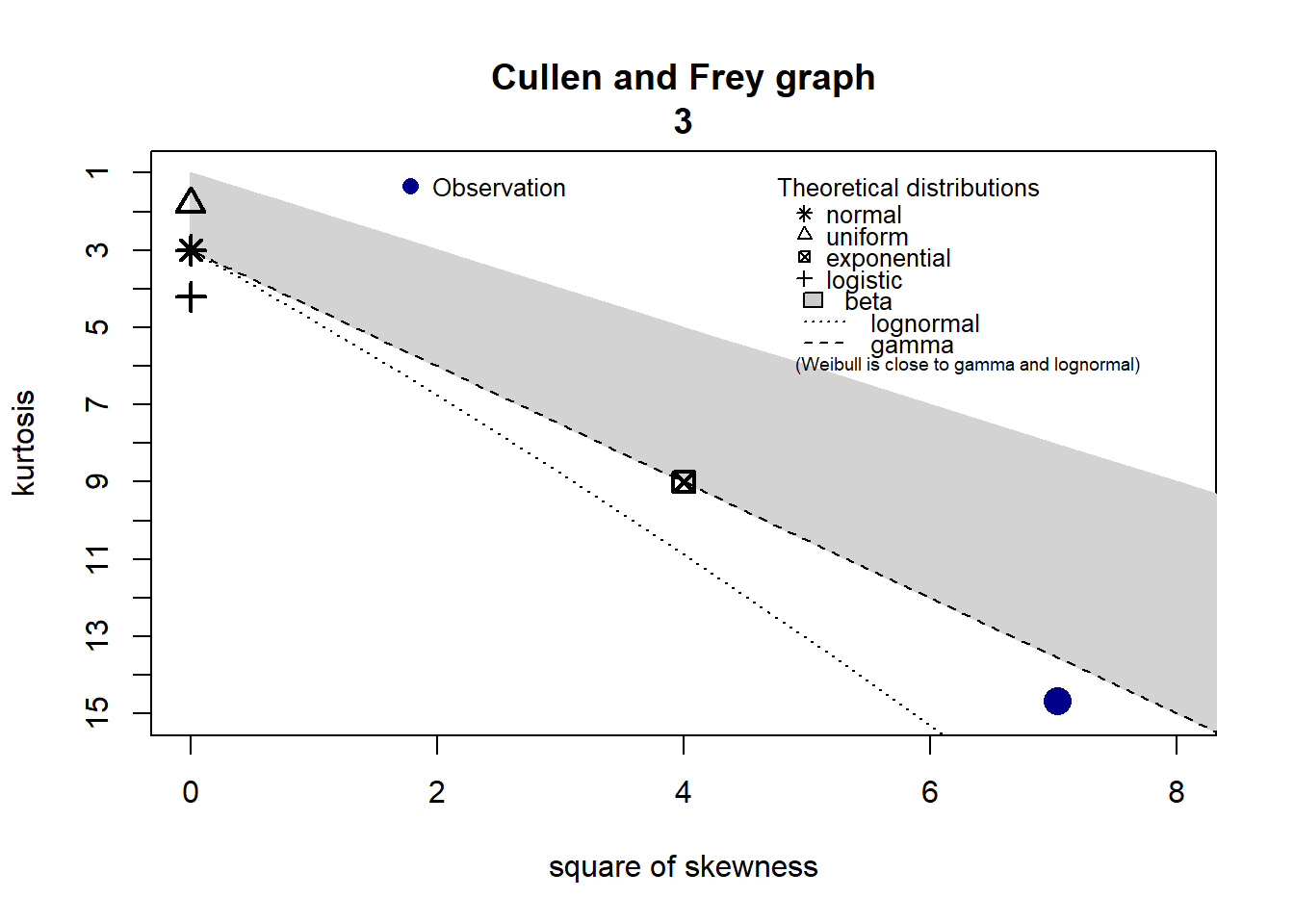
3.3.4 Adéquation loi 4
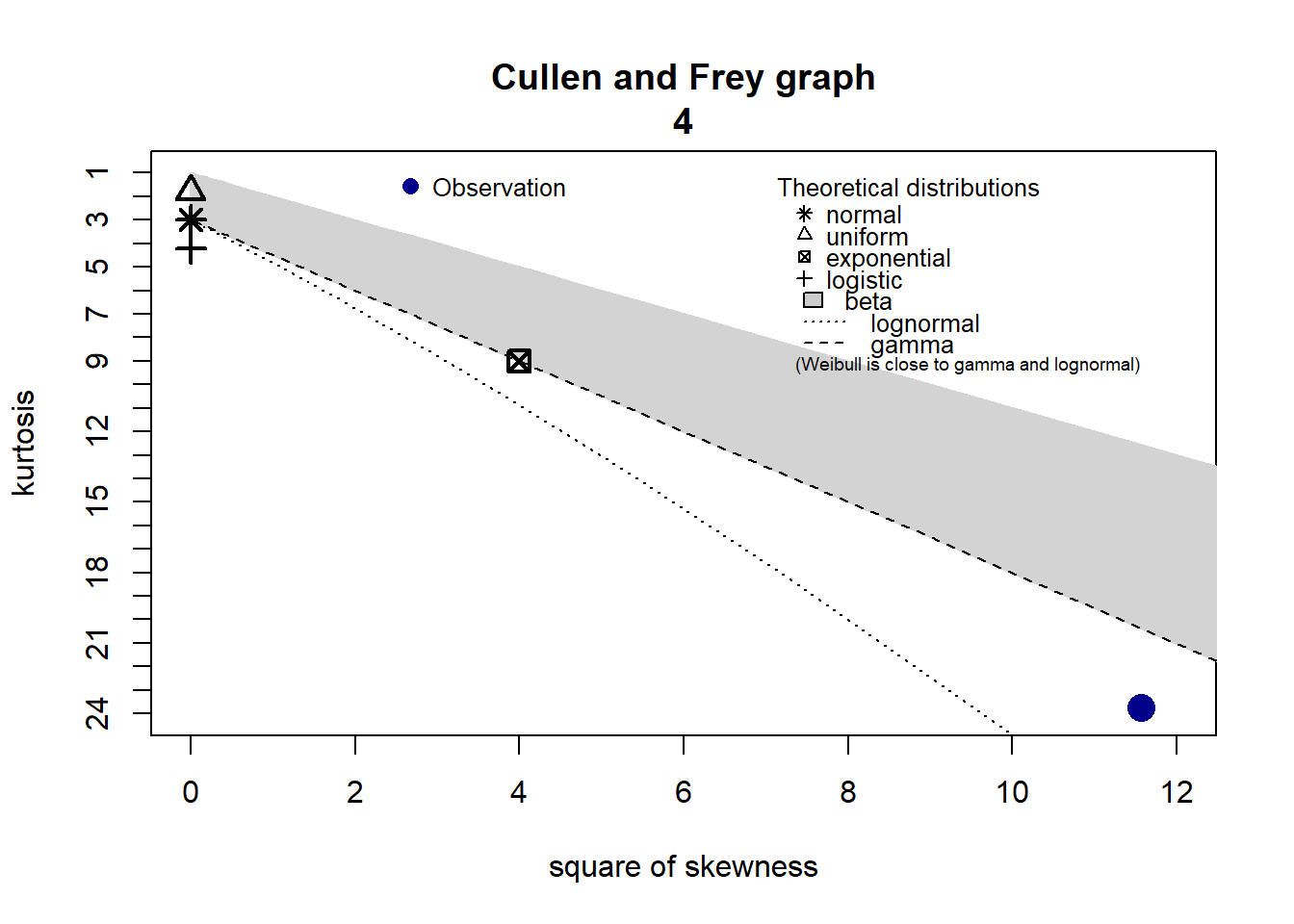
3.3.5 Adéquation loi 5