Correction des fautes d’orthographe
Les data scientists doivent 80% de leur temps à nettoyer leurs données. Les causes de la mauvaise qualité des données sont multiples. Quand la saisie est libre, les erreurs d’orthographe sont fréquentes. La correction de ces erreurs peut être consommatrice du temps. Le premier réflexe est souvent de repérer les erreurs commises et corriger. Si pour une petite quantité d’erreurs, il semble rapide de corriger à la main, il n’est pas viable de le faire pour une grande quantité de donnée. Ainsi, il est souvent préférable d’adopter une solution automatisée dès que possible.

1 Principe
1.1 Distance des mots
Prenons l’exemple des adresses non normalisées: on peut écrire “bld” pour “boulevard”. On peut repérer tous les “bld” et les corriger. Mais le problème, c’est que certains écrivent “blvd”. Puis pour “avenue”, on peut trouver “av”, “ave”, “aven”, “avenu” et d’autres erreurs grossières.
On peut calculer la distance entre deux mots. Une façon de compter peut être la suivante:
- On compte le nombre de lettres dans chaque mot.
- Si le nombre de lettres pour une lettre donnée est identique, la différence est de 0. Si le nombre est différent, on prend la valeur absolue de la différence.
- A la fin, on additionne le nombre de différences.
Par exemple,
- entre “rue” et “avenue”, on a une distance de 5
- entre “boulevard” et “bld”, on a une distance de 6
1.2 Correction
Pour automatiser la correction, on peut procéder aux étapes suivantes:
- On doit d’abord avoir les types de voies normalisées, par exemple “avenue, rue, boulevard”.
- Pour chaque type de voie observé, on peut calculer la distance avec les types normalisés. Pour “av”, on aura donc “4, 5, 7”.
- On prend le minimum, et ici, on obtient bien “avenue”.
1.3 Types de distance
Imaginons le cas suivant:
- Dans ma base, j’ai deux rues
- “rue Victor Hugo” et
- “rue Hugo Viktor”
- Quelqu’un écrit “rue Viktor Hugo” et on suppose qu’il s’est trompé sur la lettre “k” (si ce cas vous apparait ambigu, vous pouvez toujours imaginer un autre cas où l’ordre est important).
- Si on calcule la distance comme précédent, on aura comme distance par rapport aux données de référence: 2, 0. Du coup, la proche serait “rue Hugo Viktor”, ce qui n’est pas ce qu’on souhaitait.
- Pour résoudre le problème, on peut utiliser un autre type de distance: distance Levenshtein, et on aura 1, 10.
On voit que selon les cas, on peut choisir le bon type de distance pour mieux traiter nos erreurs.
2 Clustering
Si on n’a pas des données de référence, on peut faire une segmentation des mots.
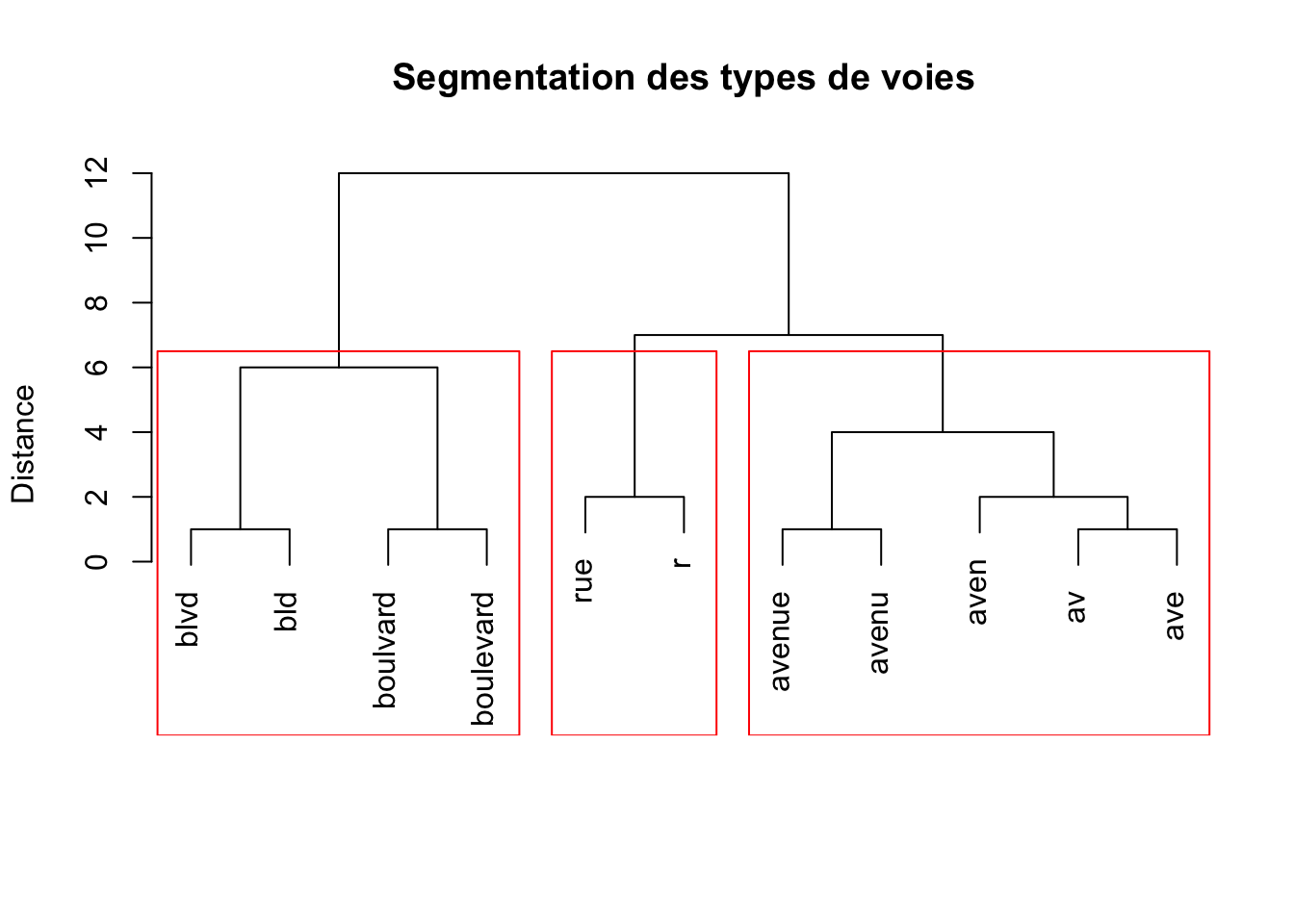
3 Extraction du code postal
Un autre exemple de manipulation des adresses est l’extraction des codes postaux. On a un ensemble d’adresses avec numéro de rue, nom de rue, code postal et ville dans une même chaîne de caractères. Si on veut extraire le code postal à la main, la tâche peut s’avérer très consommatrice de temps.
| noms | adresse |
|---|---|
| McDonald’s AMBERIEU | Rue Alexandre Bérard 01500 AMBERIEU EN BUGEY |
| McDonald’s BELLEY | Rond-point RN504 01300 BELLEY |
| McDonald’s BEYNOST | ZAC des Baterses 01700 BEYNOST |
| McDonald’s BOURG EN BRESSE | 8-10 Avenue des Sports 01000 BOURG EN BRESSE |
| McDonald’s CHATILLON EN MICHAILLE | Avenue De Lattre de Tassigny 01200 CHATILLON EN MICHAILLE |
| McDonald’s FERNEY VOLTAIRE | Route de Meyrin 01210 FERNEY VOLTAIRE |
On peut utiliser R pour le faire automatiquement.
| noms | adresse | cp |
|---|---|---|
| McDonald’s AMBERIEU | Rue Alexandre Bérard 01500 AMBERIEU EN BUGEY | 01500 |
| McDonald’s BELLEY | Rond-point RN504 01300 BELLEY | 01300 |
| McDonald’s BEYNOST | ZAC des Baterses 01700 BEYNOST | 01700 |
| McDonald’s BOURG EN BRESSE | 8-10 Avenue des Sports 01000 BOURG EN BRESSE | 01000 |
| McDonald’s CHATILLON EN MICHAILLE | Avenue De Lattre de Tassigny 01200 CHATILLON EN MICHAILLE | 01200 |
| McDonald’s FERNEY VOLTAIRE | Route de Meyrin 01210 FERNEY VOLTAIRE | 01210 |
Aussi, il est possible de séparer tous les éléments de l’adresse.
4 Outils
- R avec ses packages
- OpenRefine
- Le mieux, c’est de traiter en amont, en donnant une liste de référence.
Copyright © 2016 Blog de Kezhan Shi