Analyse de l’élection présidentielle 2017
1 Introduction
Pratiquement tous les journaux ont publié des statistiques des résultats du premier tour des élections présidentielles, parfois avec des visualisations par commune. La visualisation de toutes les communes de France donne une carte assez coloriée. De prime abord, ça a l’air impressionnant. Cependant comme je ne connais pas assez bien toutes les communes de France, je n’arrive pas à comprendre la signfication de la visualisation. De plus, dans les grandes villes, les résultats sont souvent différents en fonction des quartiers. Si on essaie de visualiser les résutlats des quartiers sur une carte nationale, ça devient illisible. Si on prend la moyenne au niveau de la ville, on perd de l’information.

En revanche, à l’échelle de Paris, c’est plus parlant pour moi:

Pourquoi? Parce que je connais certaines caractaristiques des différents arrondissements: niveau de revenu, prix immobilier, niveau d’éducation, etc.
Ainsi, pour analyser les résultats de toutes les communes, on peut peut-être visualiser les votes en fonction de ces caractéristiques…
2 Voix du premier tour
Les données sont issues du ministère de l’intérieur, et représentent les votes par commune. Les données démographiques sont celles de 2012, disponibles sur l’insee.
2.1 Statistiques globales
On peut réaliser la densité de distribution des pourcentages de votes par commune pour les 4 candidats qui ont obtenu le plus voix.
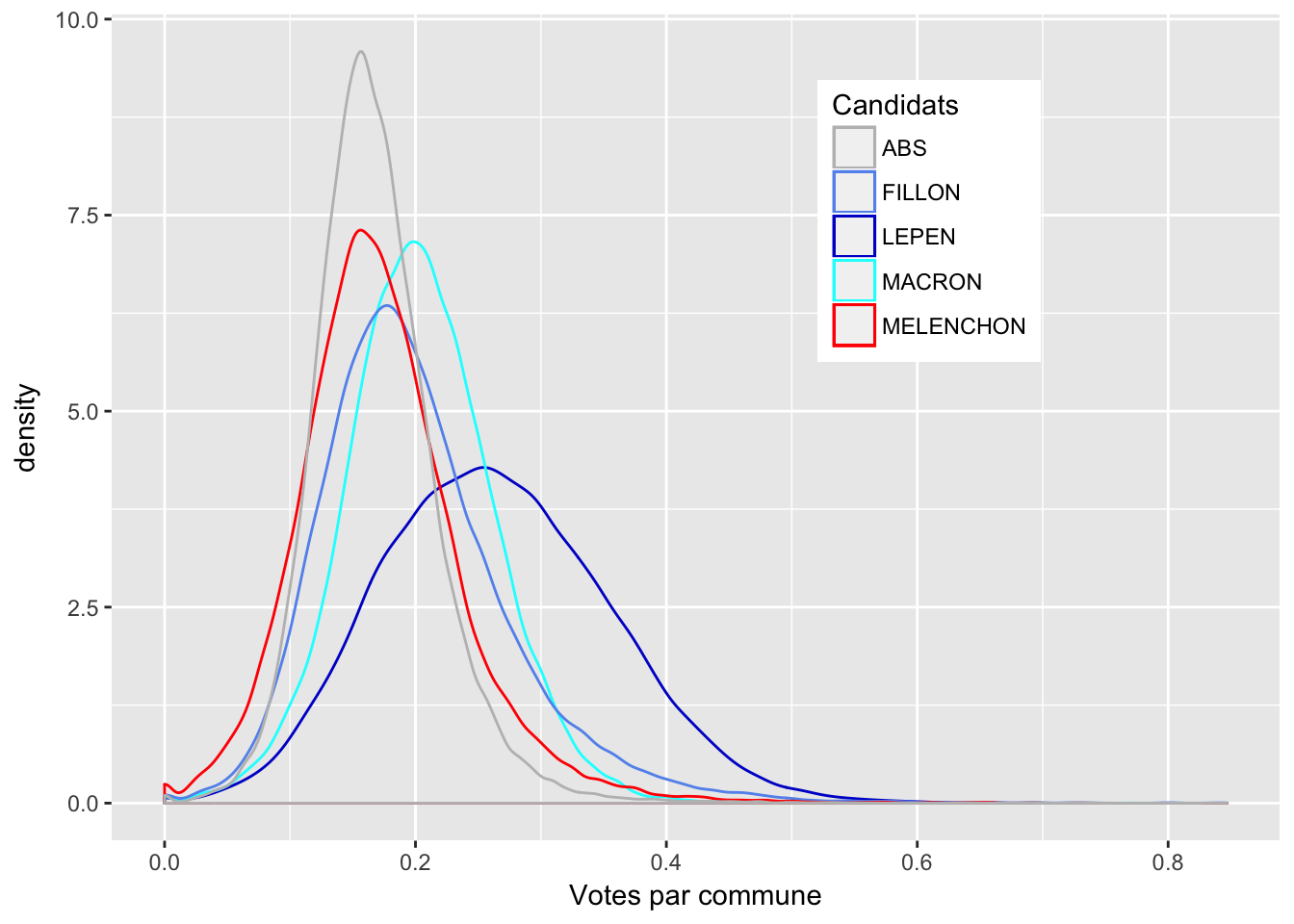
On peut remarquer une grande volatilité pour Marine Le Pen.
Le résumé statistique des votes par communes se présente comme suit:
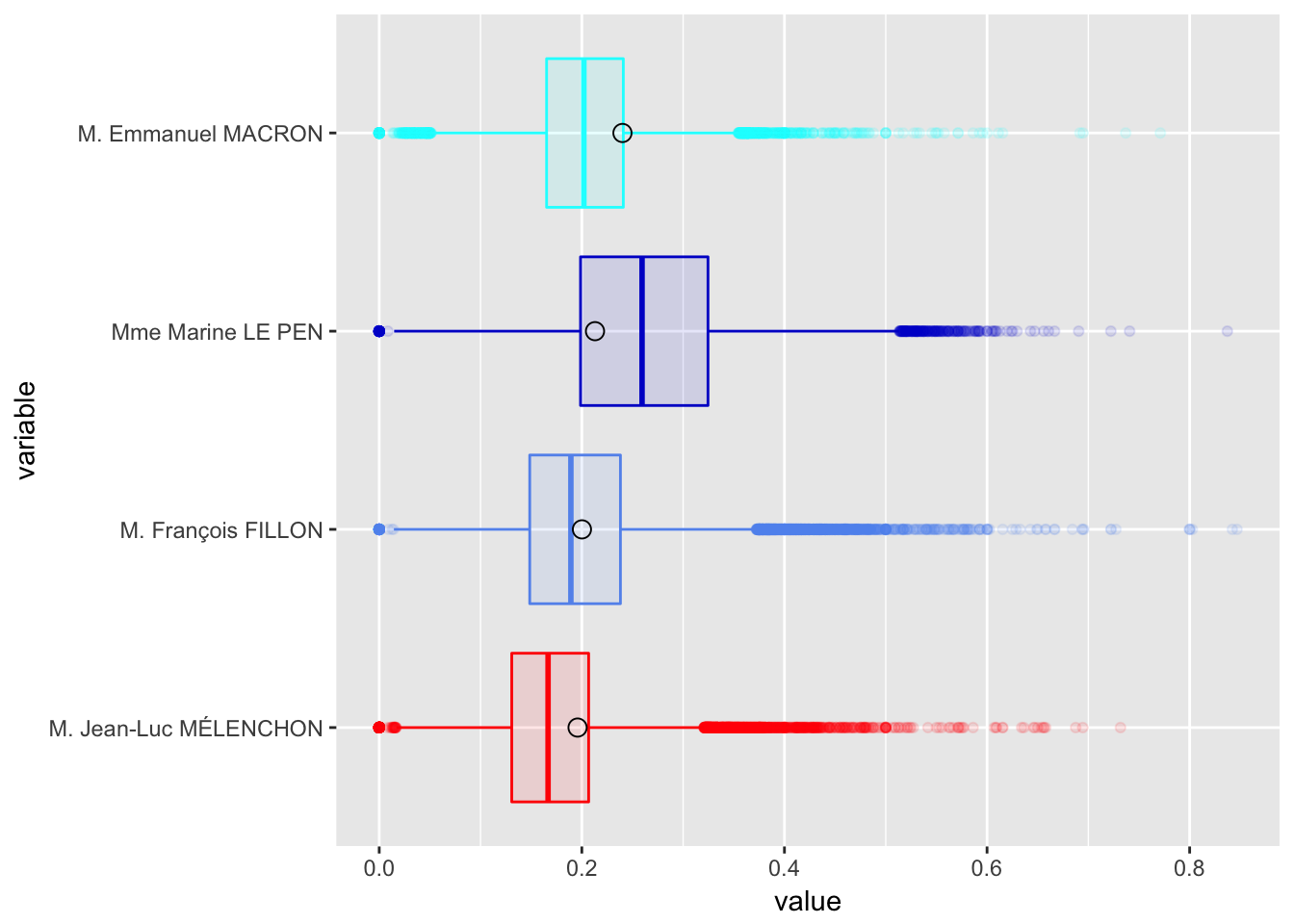
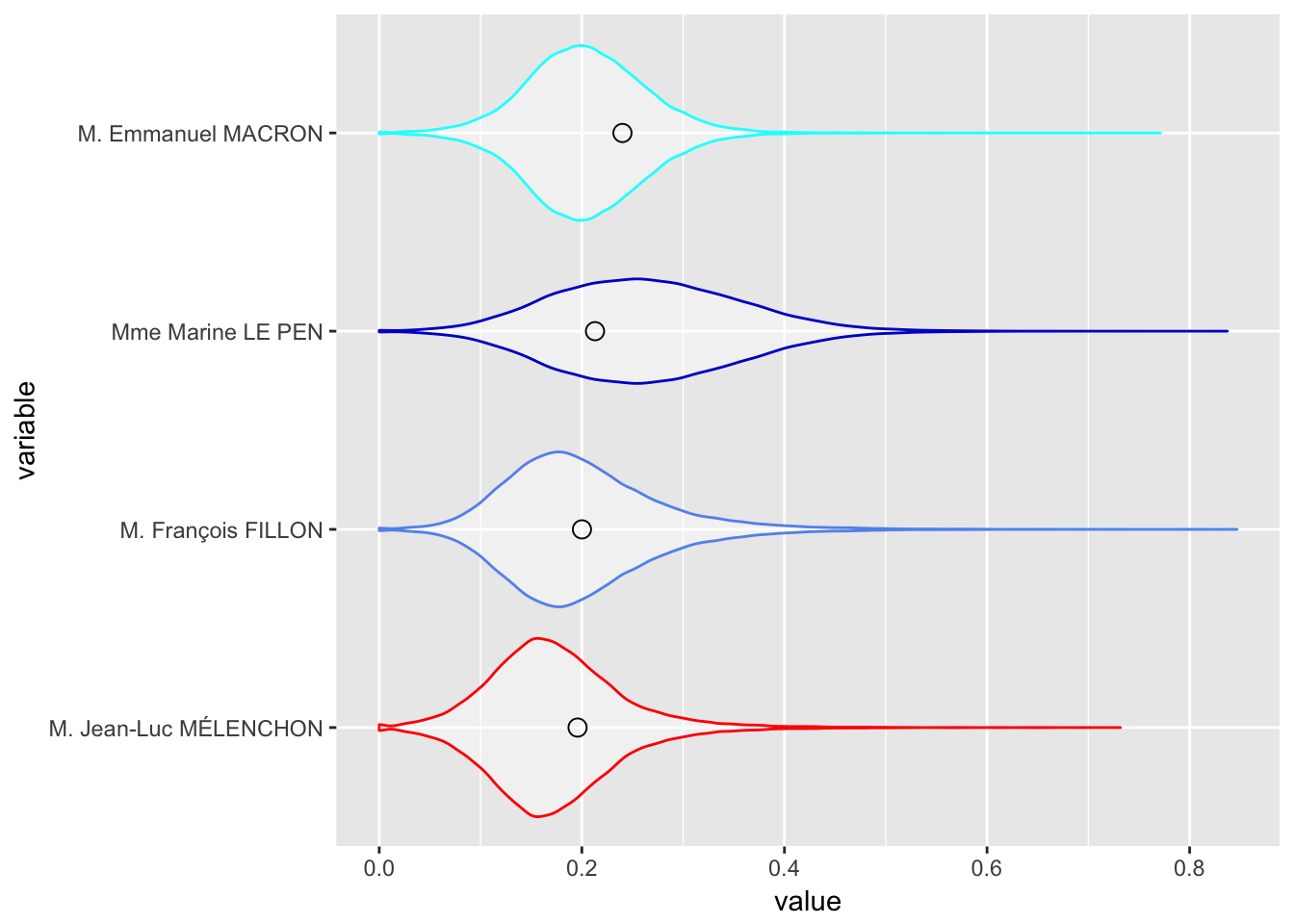
NB: La moyenne ici est la moyenne des votes par commune. Pour retrouver les moyennes nationales, il faut pondérer par la population.
2.2 Typologies des communes
Grâce au travail de Fabien Couprie sur la typologie des communues, on peut aggréer les voix en fonction de ces typologies.
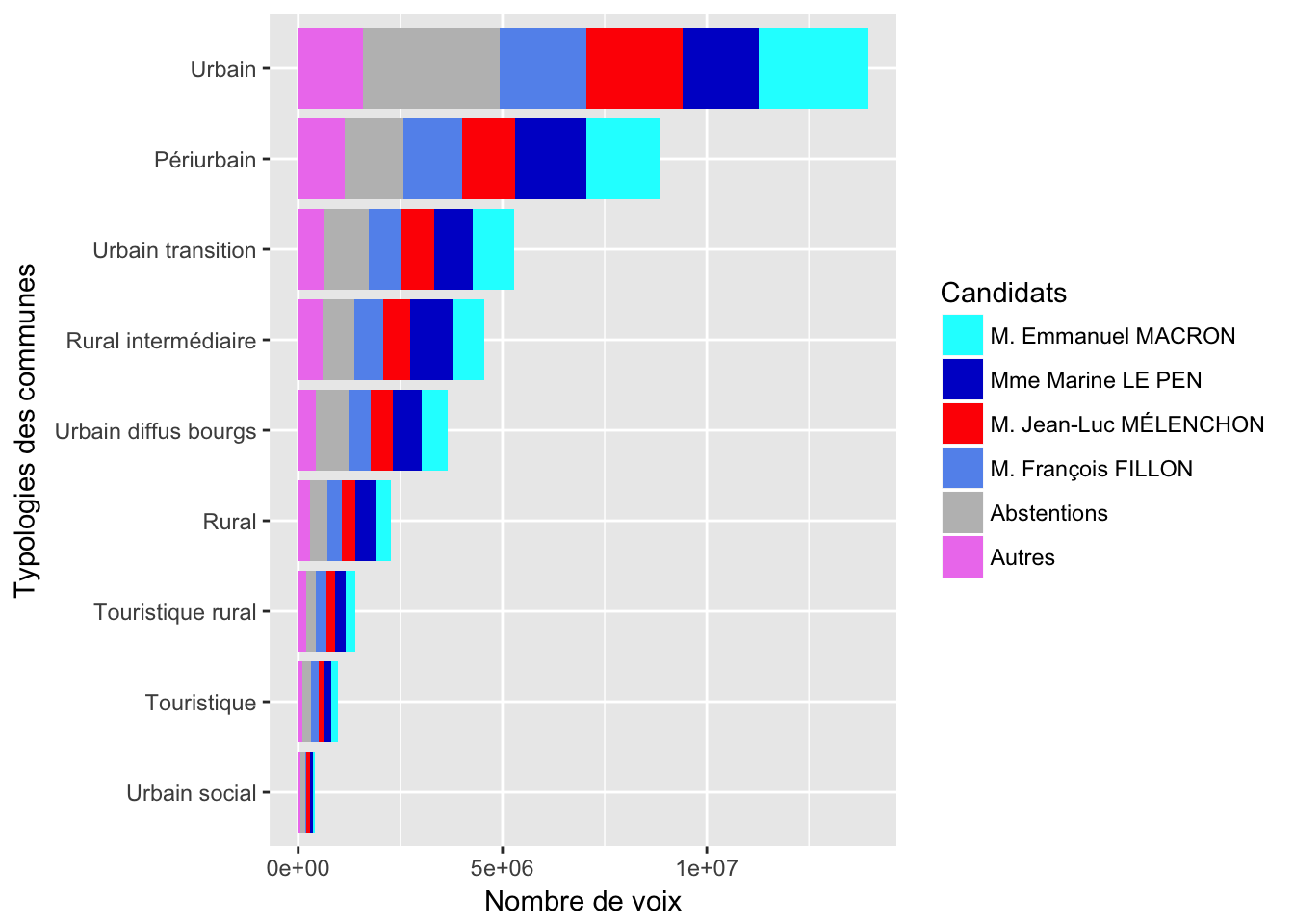
A cause de la variation du total par typologie, on n’arrive pas à voir clairement les pourcentages, on peut visualiser uniquement les proportions:
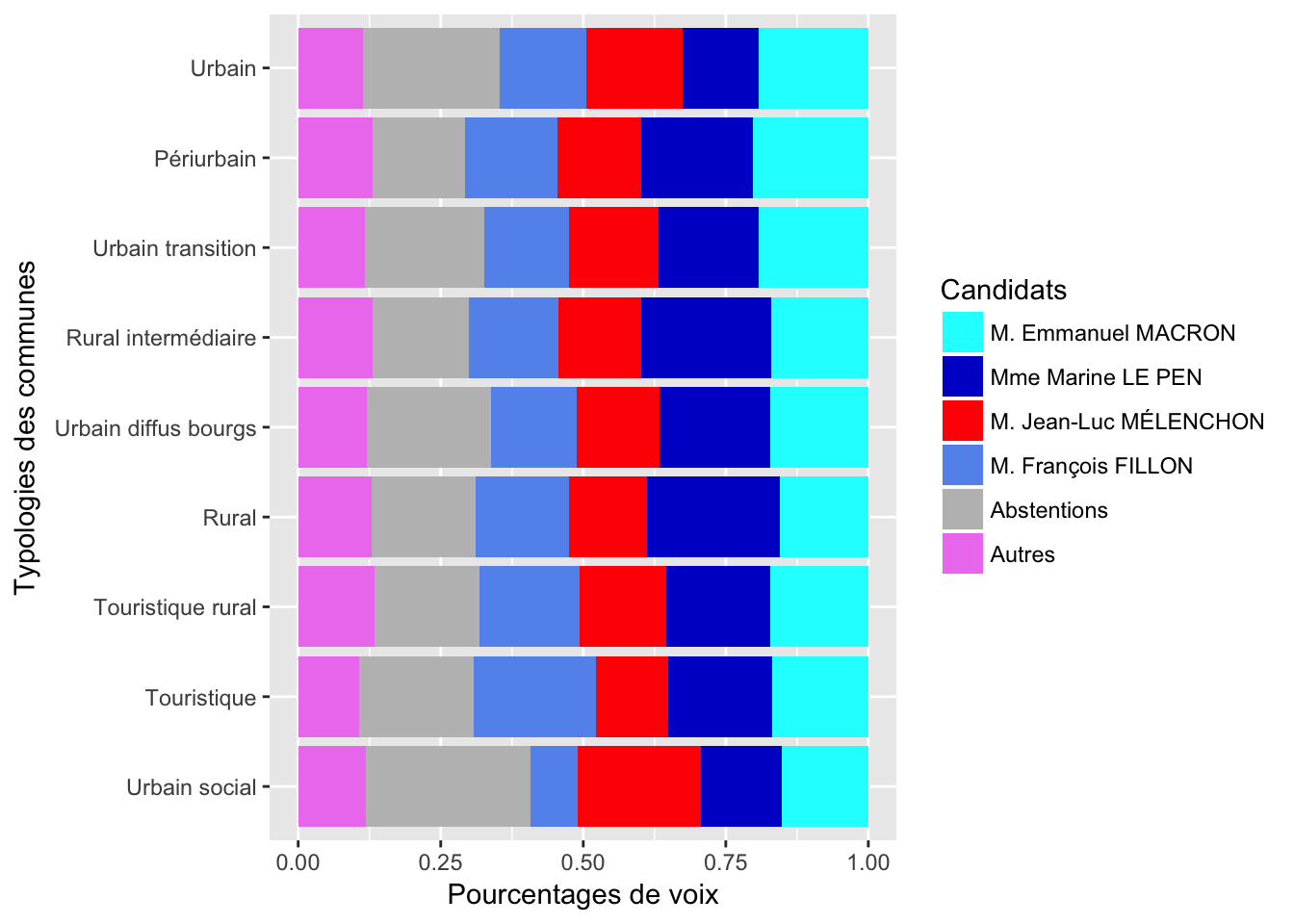
Dans la suite, on peut détailler les différents composantes typologiques des communes.
2.3 Revenus
On peut visualiser les votes en fonction des revenus médians par commune:
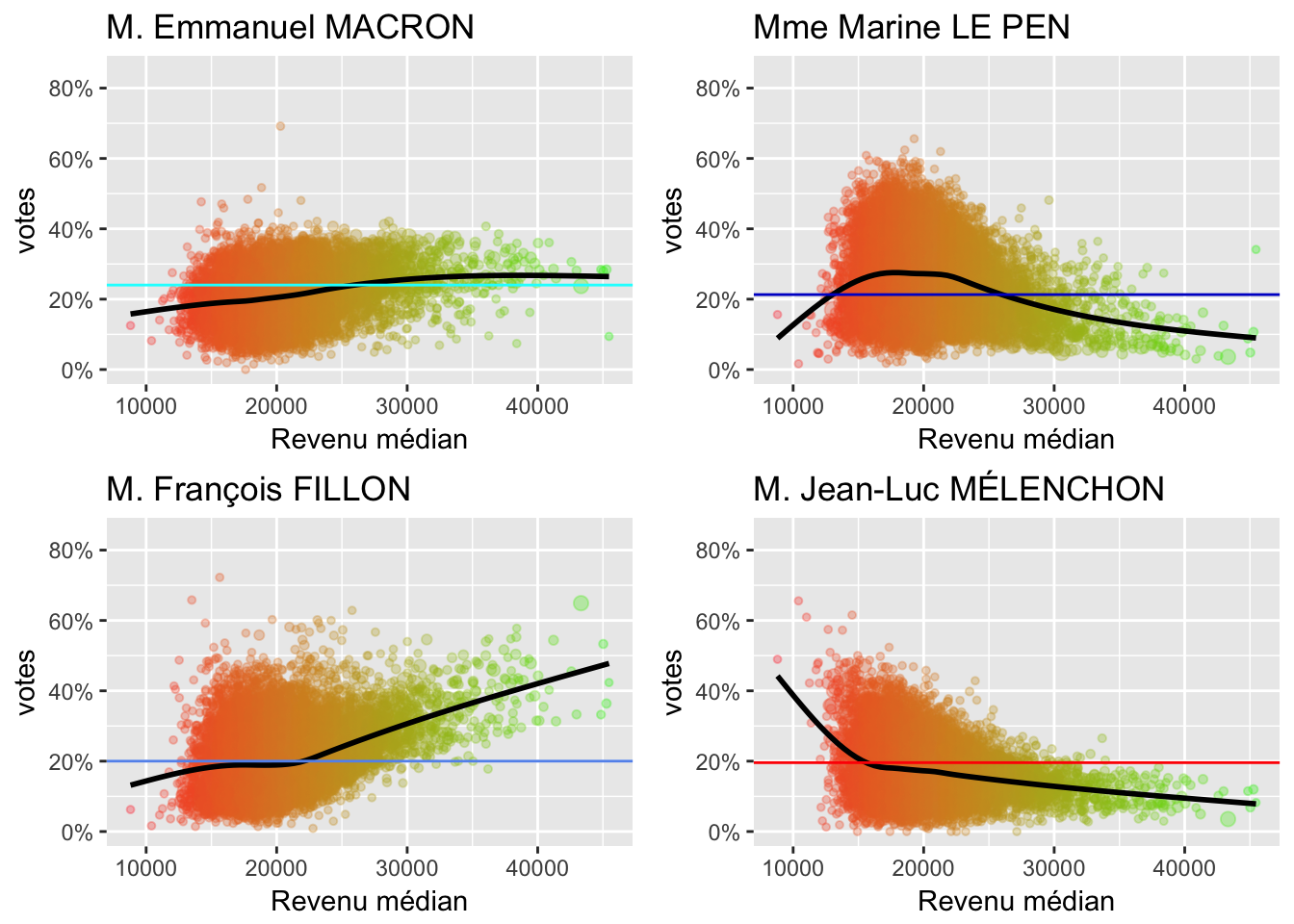
Dans toute la suite, la couleur des points indiquera le niveau de revenu:
- le vert indique la fourchette haute
- plus ça tend vers la couleur orange, plus le niveau de revenu médian de la commune baisse.
- Si c’est gris, ça indique qu’il manque les données.
Taux de pauvreté
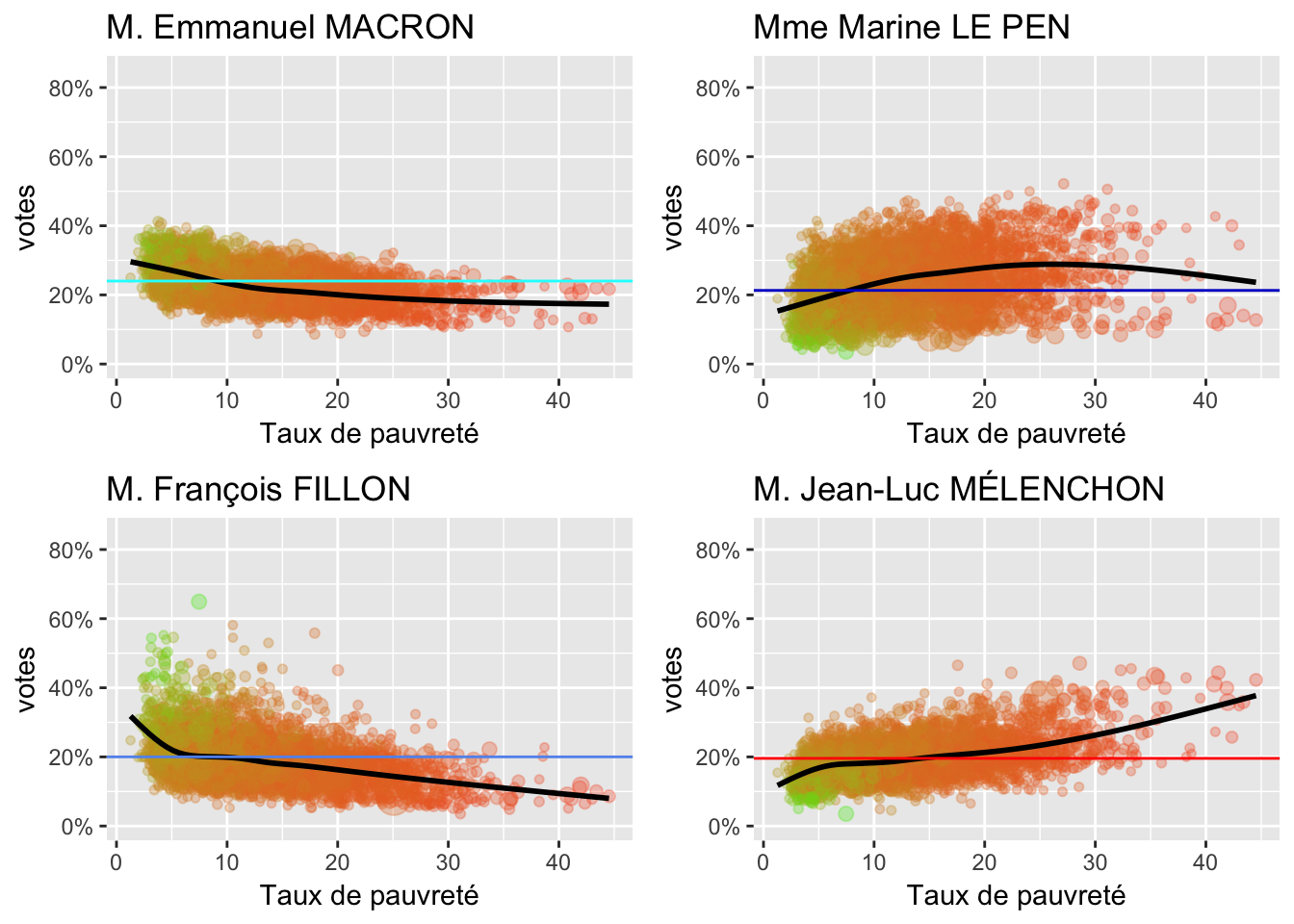
2.4 Densité de population
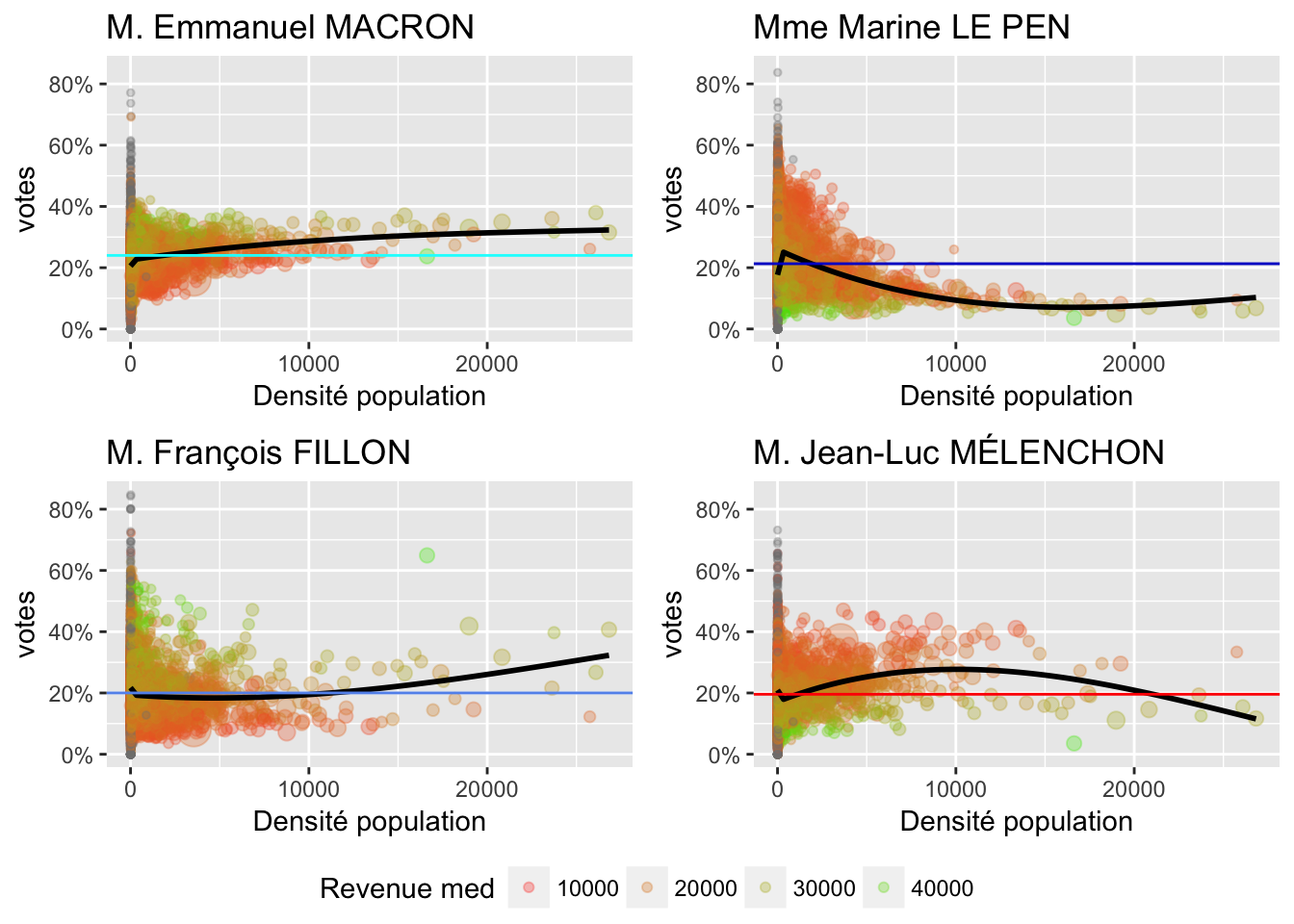
Pour cela surcharger le graphique, la taille des points représente la population totale de la commune. La couleur représente le niveau de revenue médian.
On peut adopter l’échelle logarithmique pour la densité de la population:
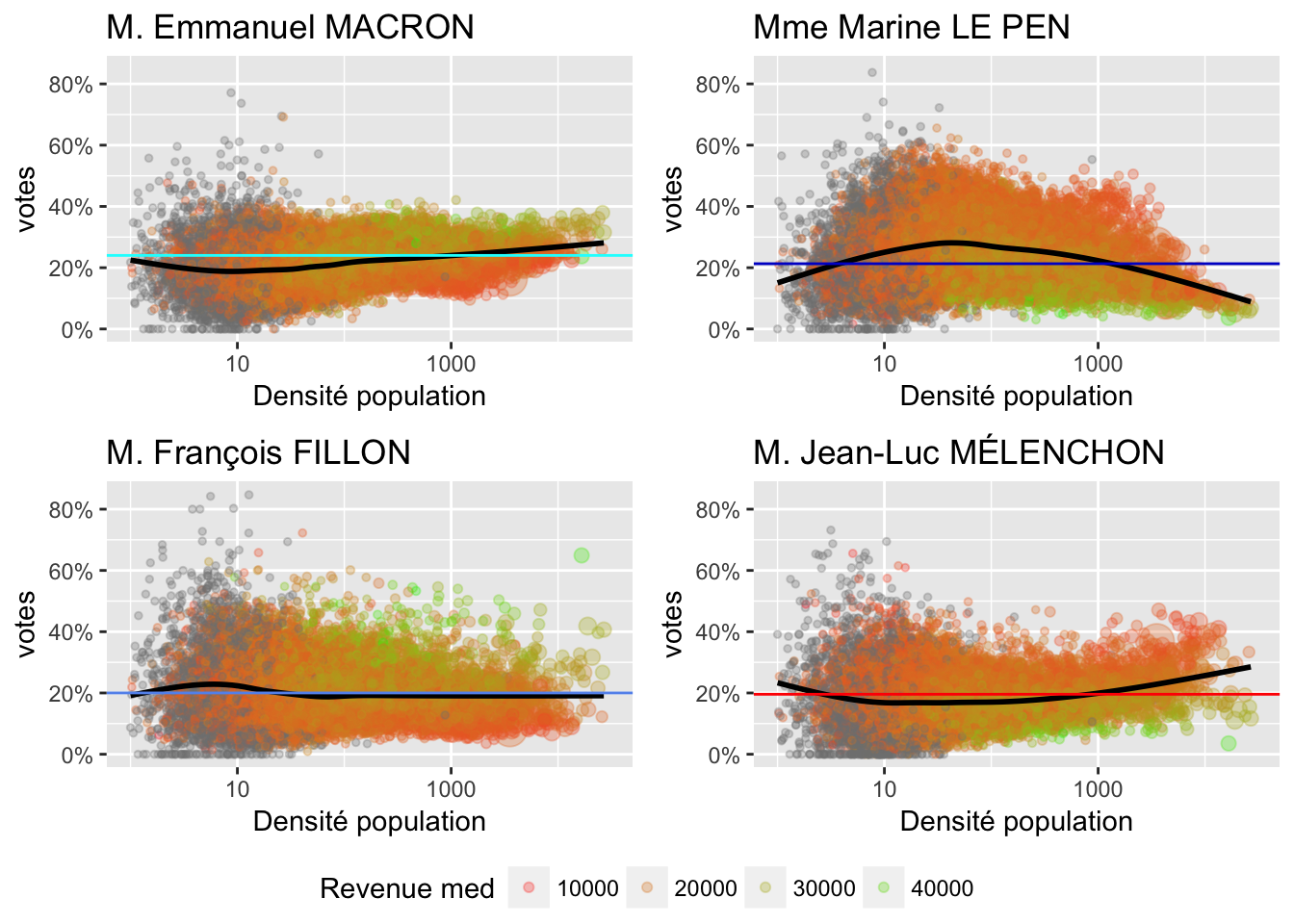
2.5 Emplois
Taux de chômage
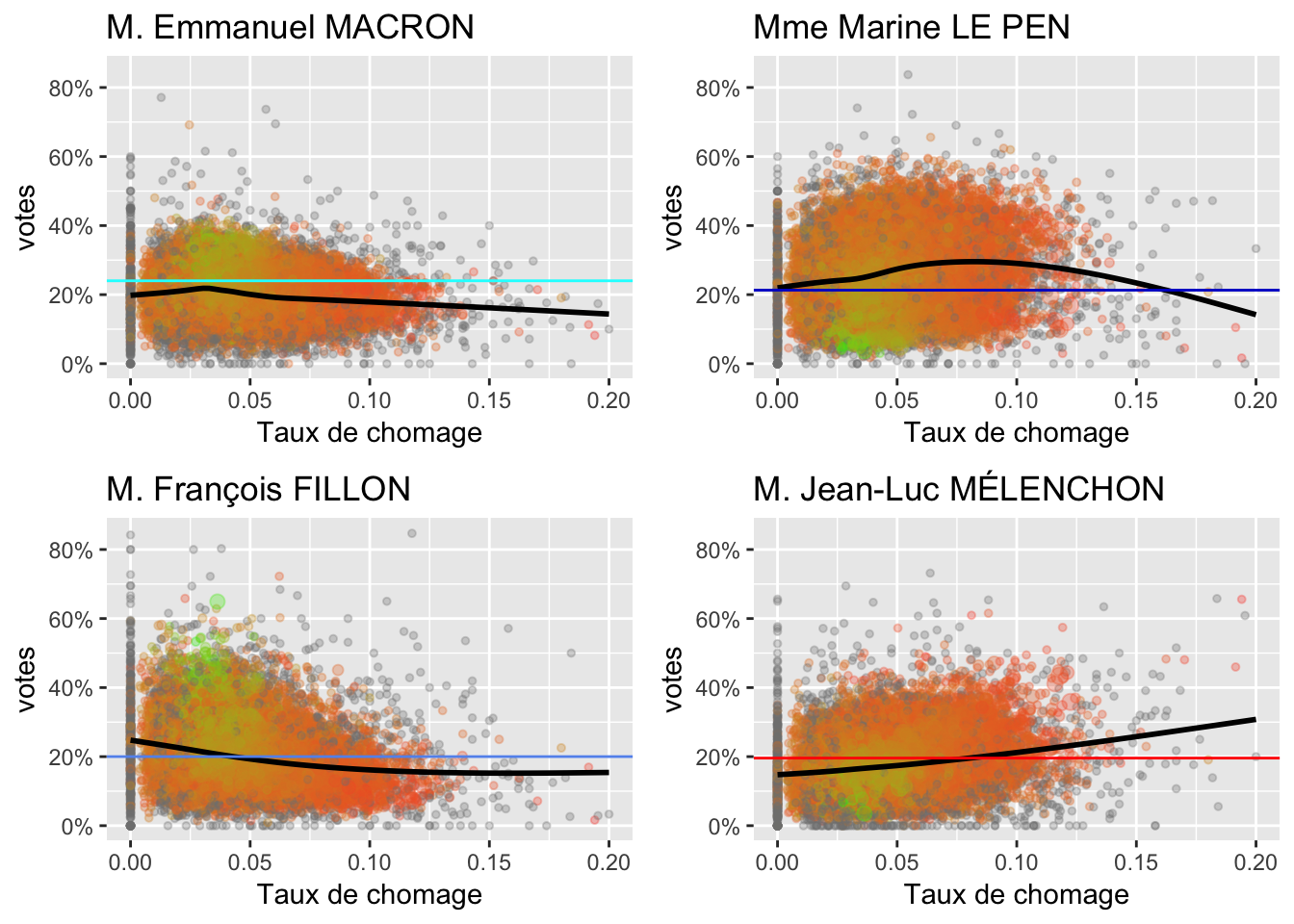
2.6 Ménages
Nombre de personnes par foyer
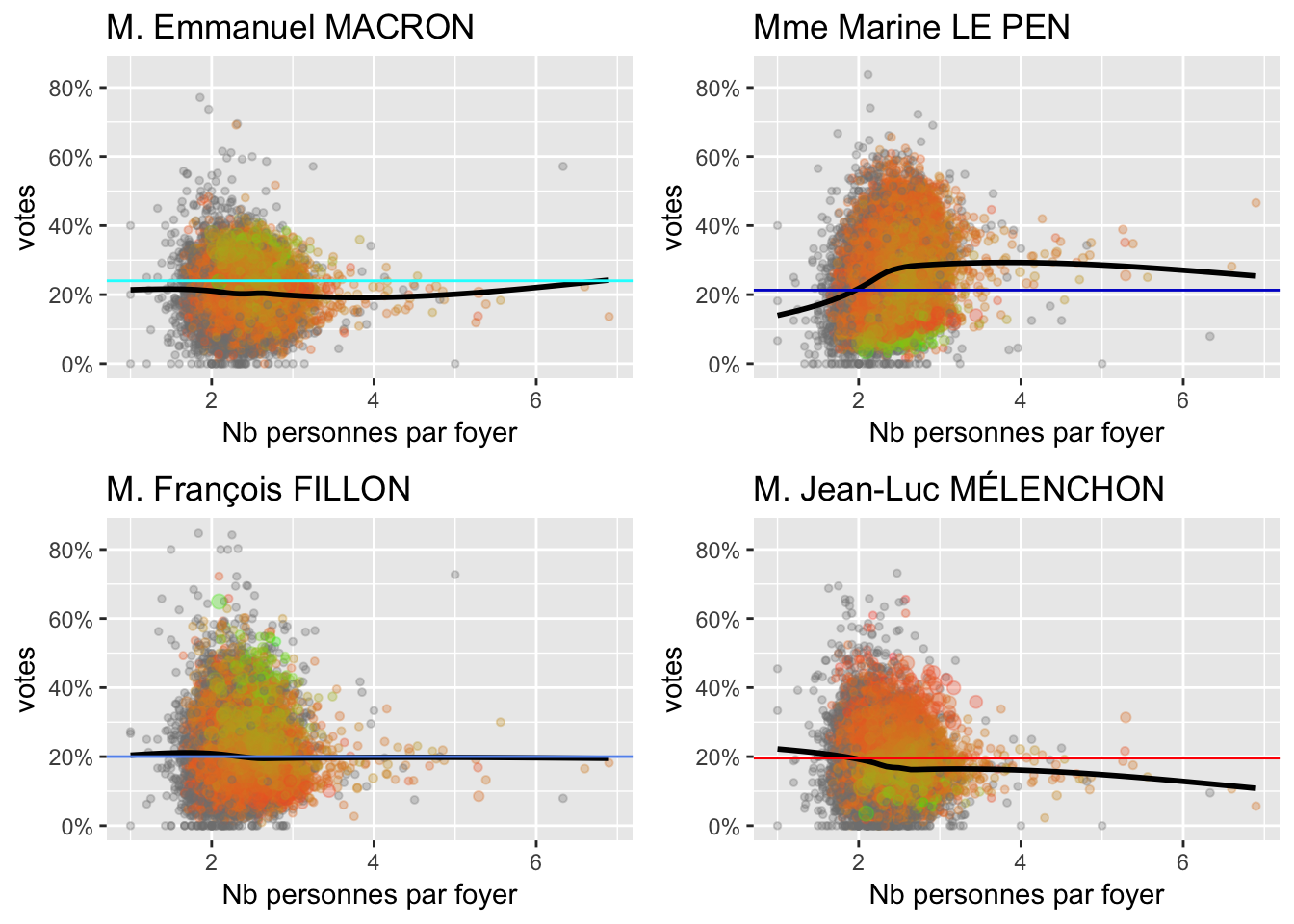
Nombre de naissances en 2013 sur la population en 2012
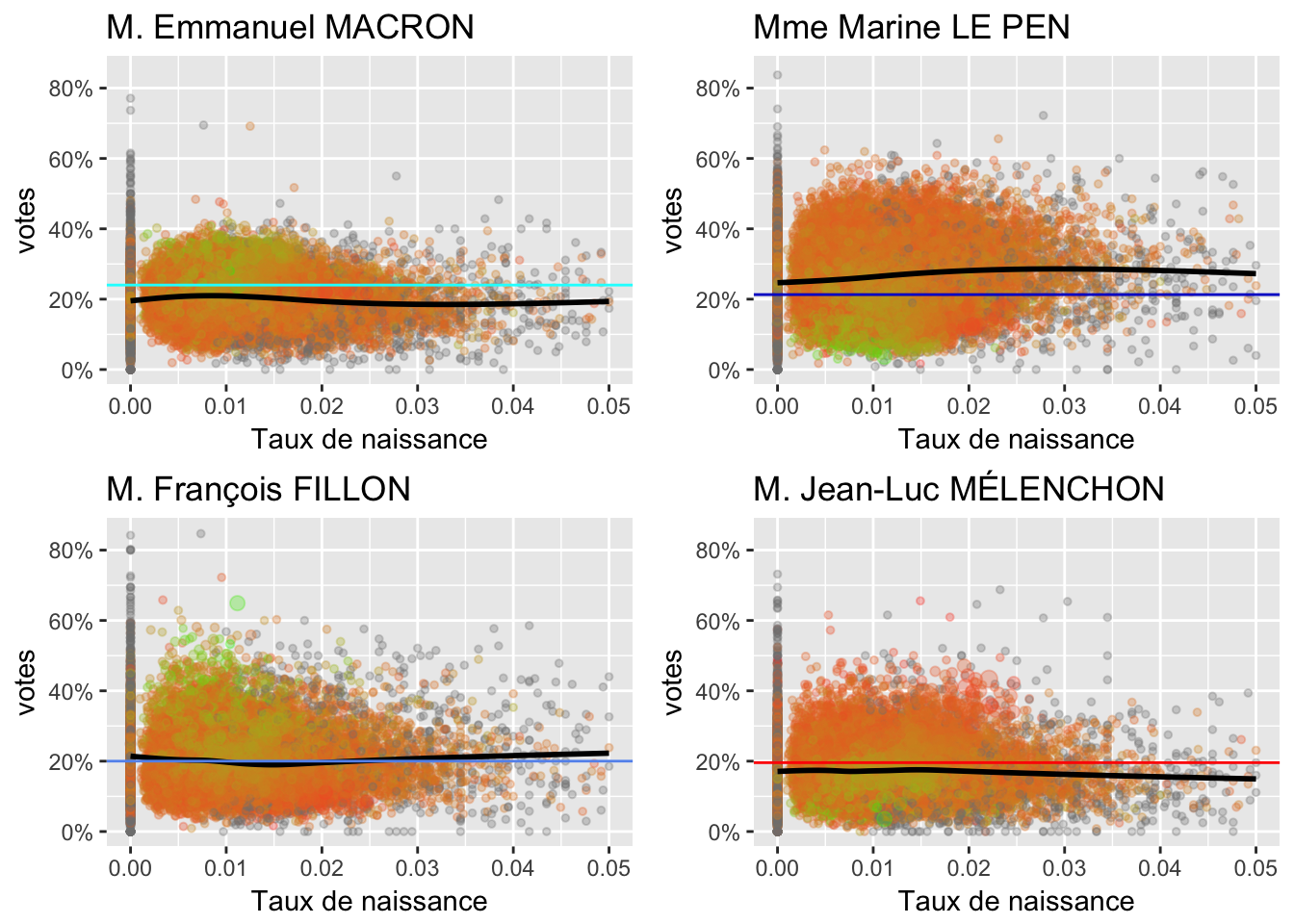
2.7 Logements
Nombre de résidences principales occupées par les propriétaires sur le total des logements
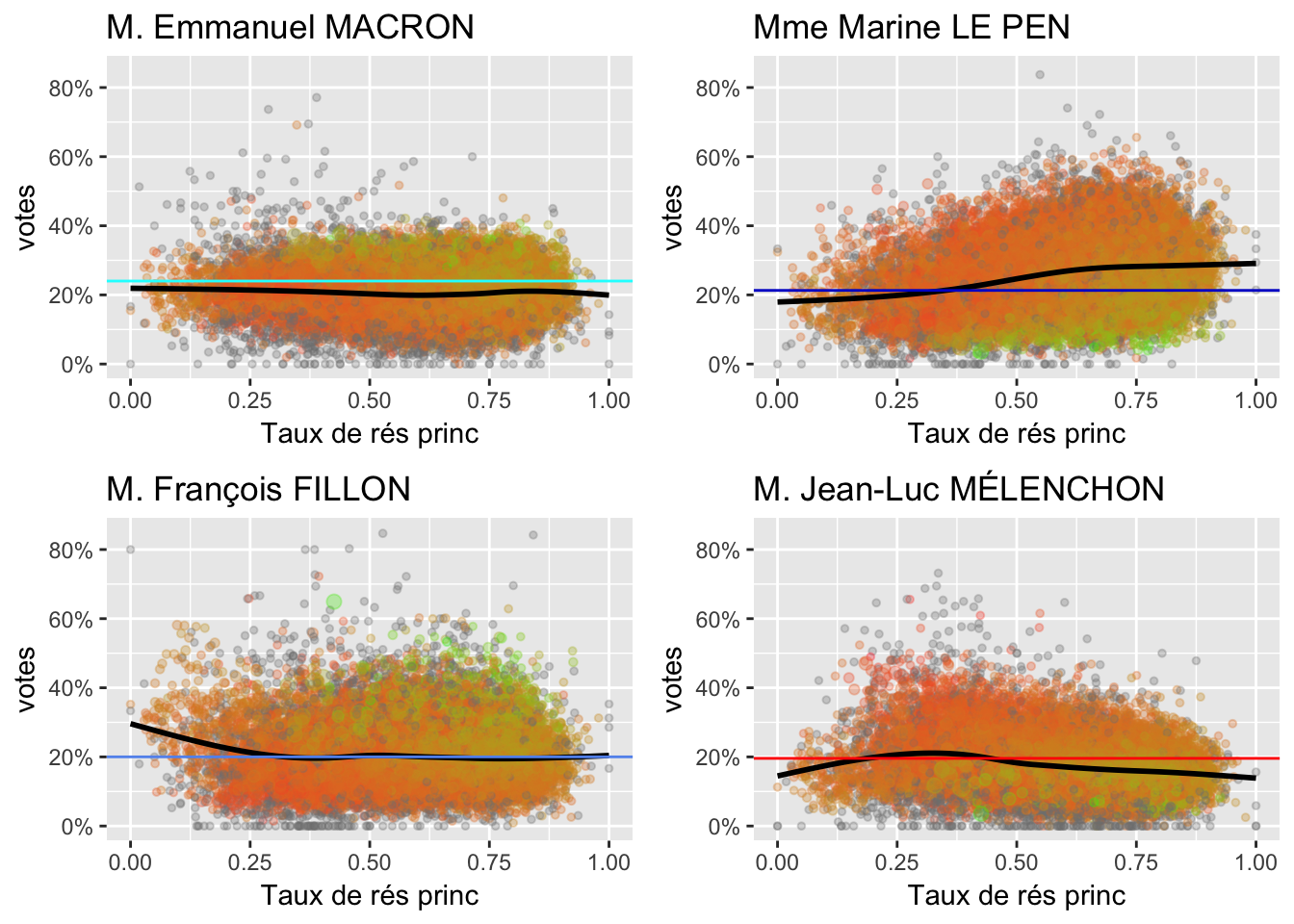
On peut remarquer aussi que les propriétaires riches votent pour Macron et les propriétaires pauvres votent pour Le Pen.
Nombre de résidences secondaires et logements occasionnels sur le total de logements
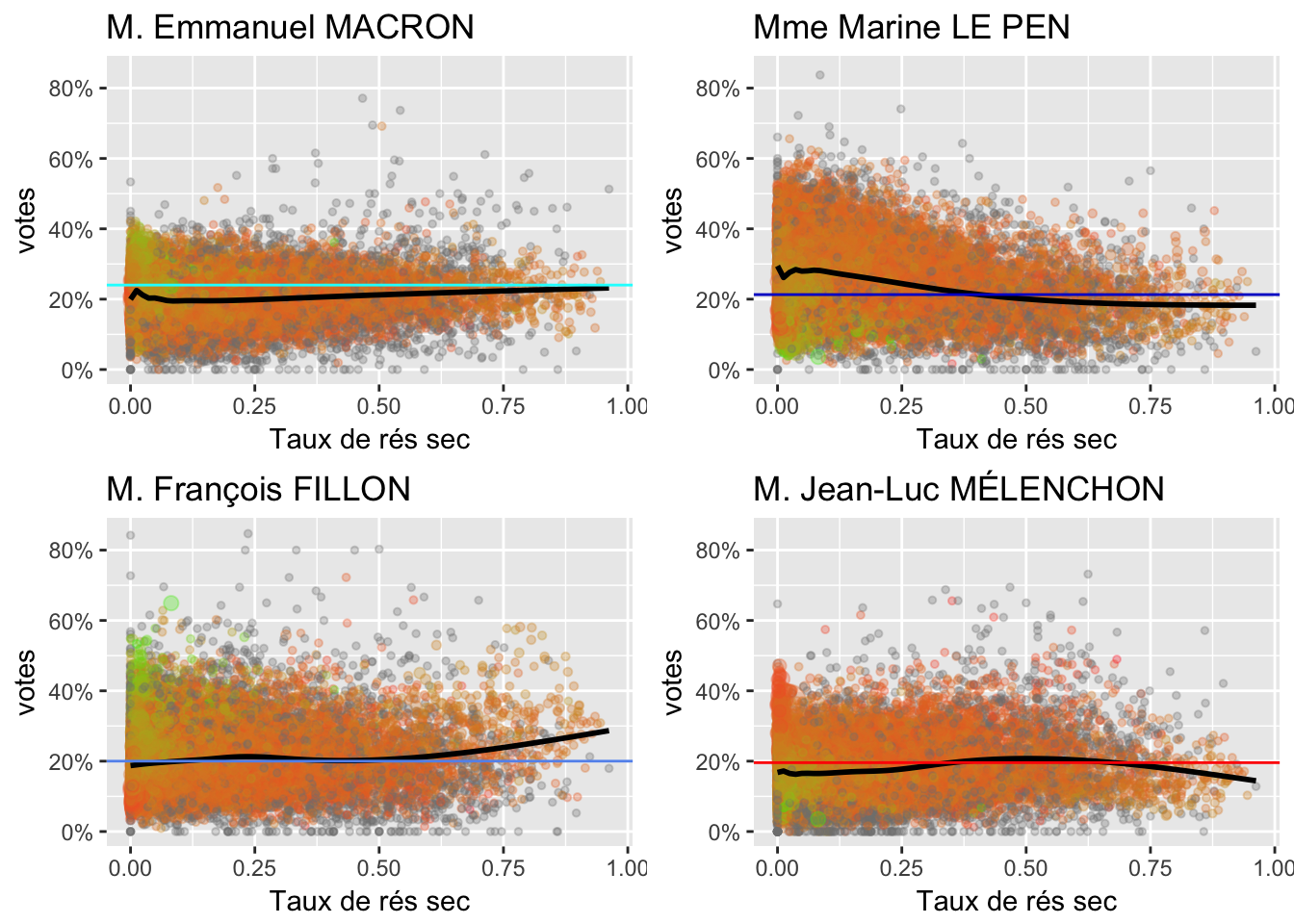
2.8 Entreprises
Pourcentages d’établissements agricoles
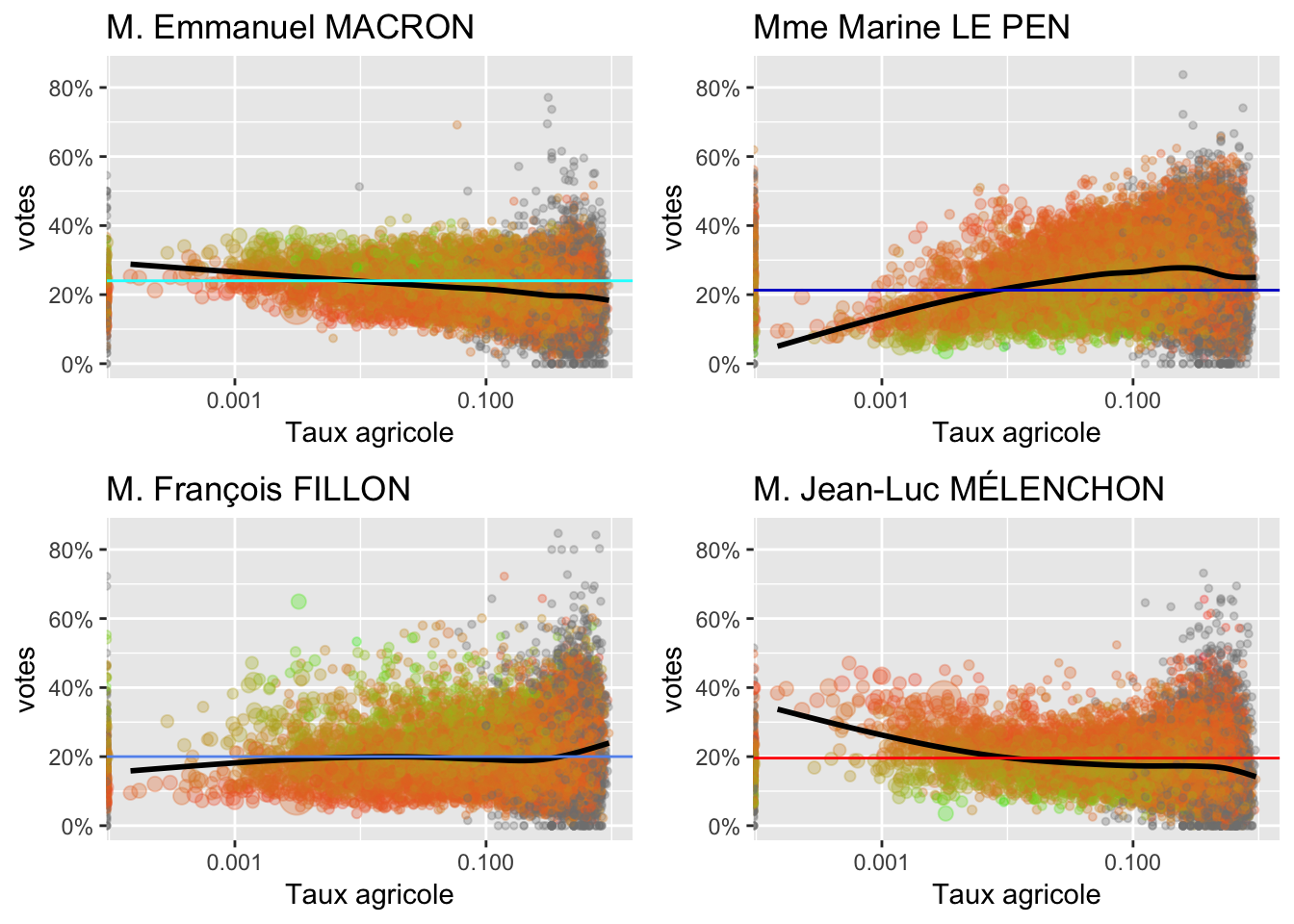
Nombre d’établissements de commerce et service sur la population en 2012
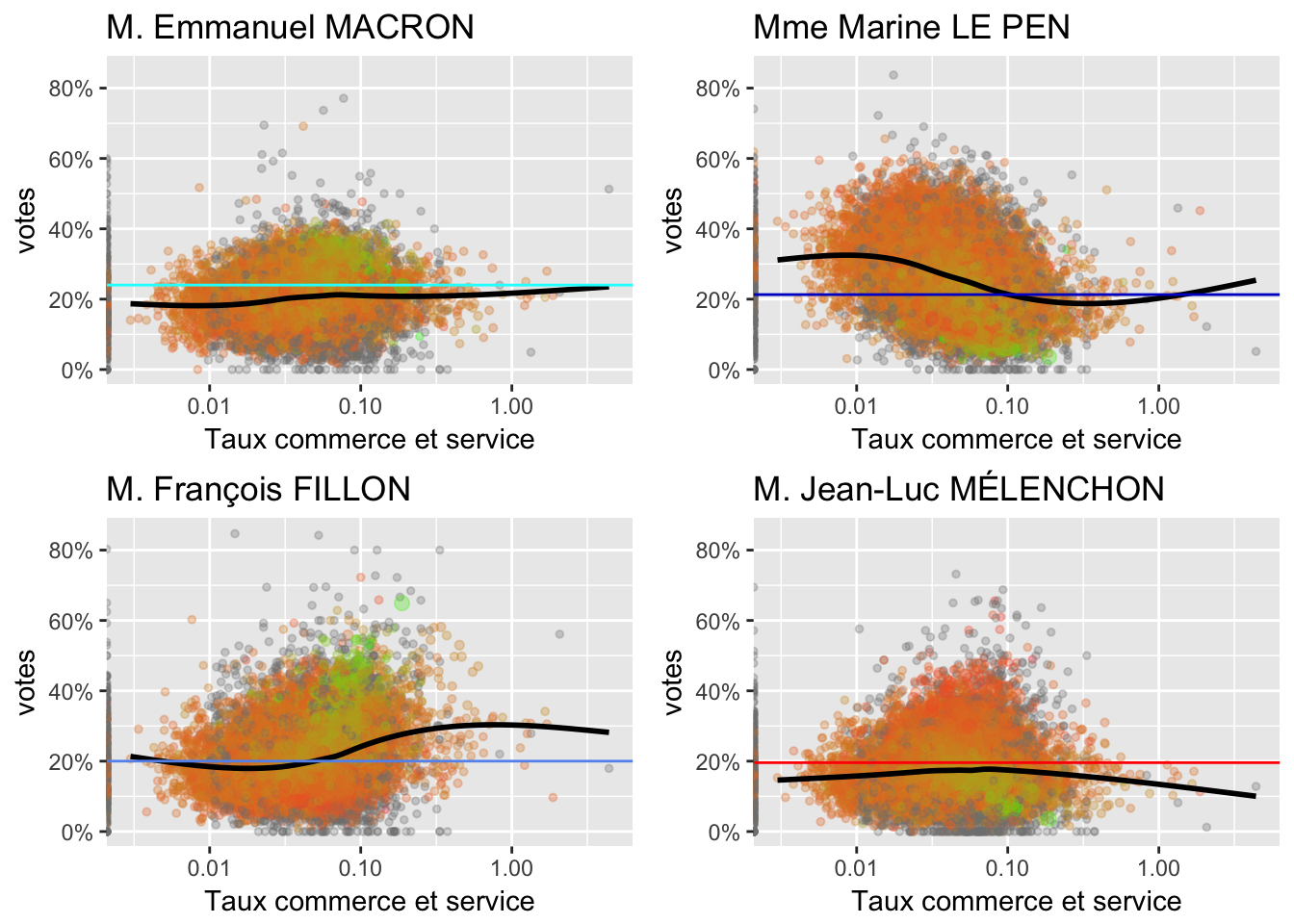
2.9 Immigration
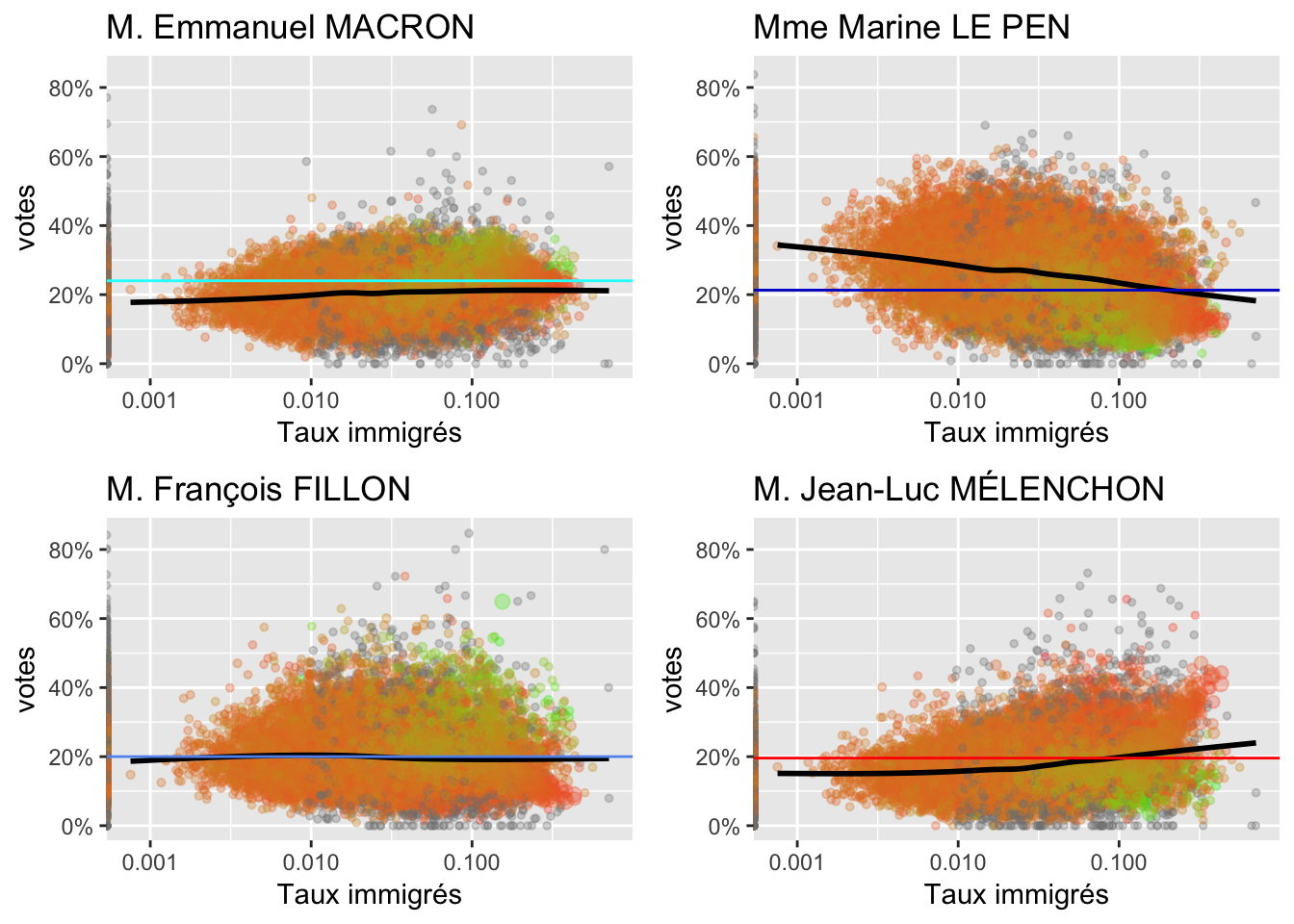
2.10 Autres
Si vous souhaitez voir les votes en fonction d’autres paramètres, n’hésitez pas à commenter.
D’autres caractéristiques peuvent être intéressantes à étudier: immigration, catégories professionnelles, taux de criminalité, etc.
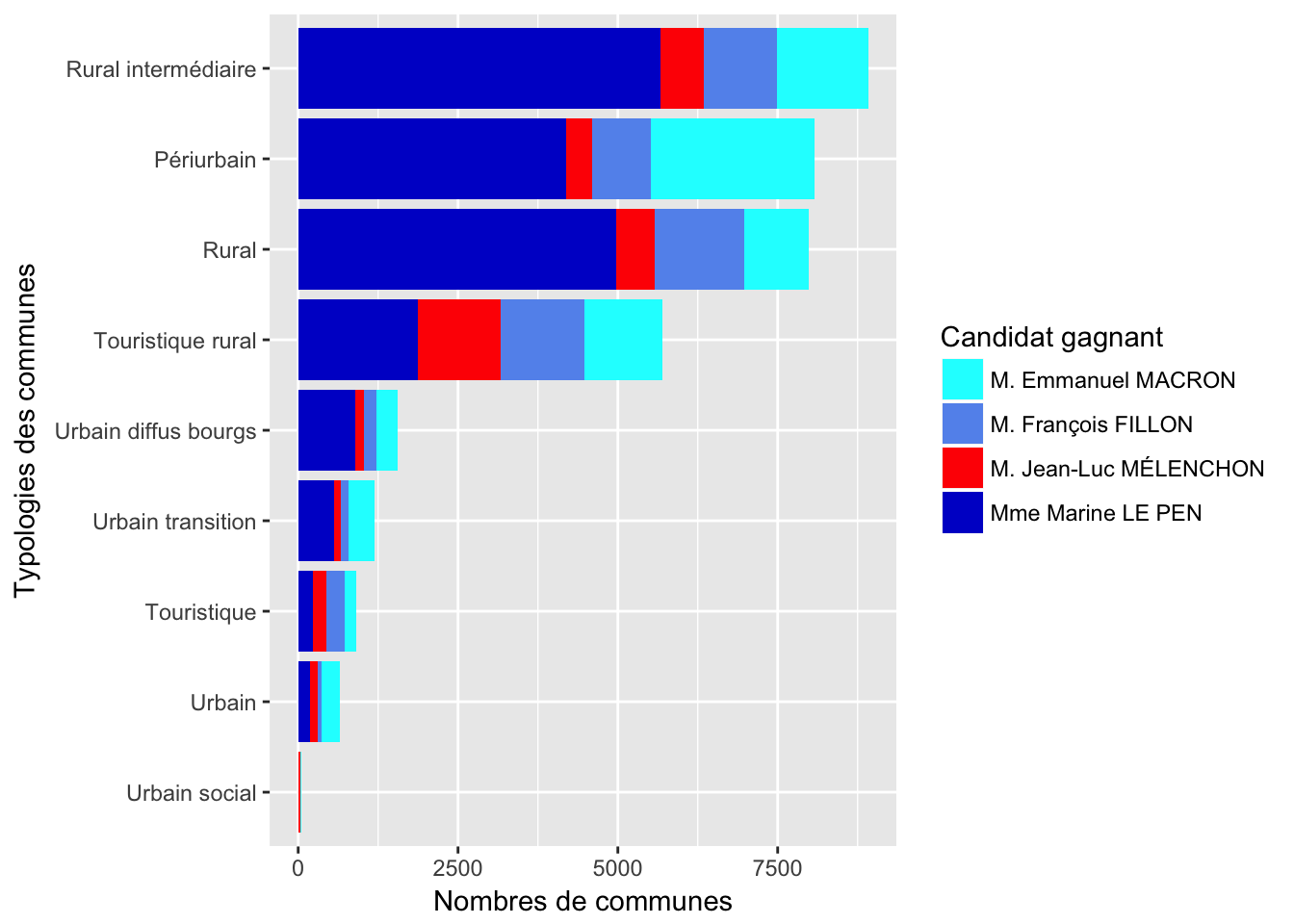
3 Gagnants par commune
On peut analyser les gagnants par commune. On ne considère pas le gagnant absolu, mais le gagnant entre les quatre principaux candidats.
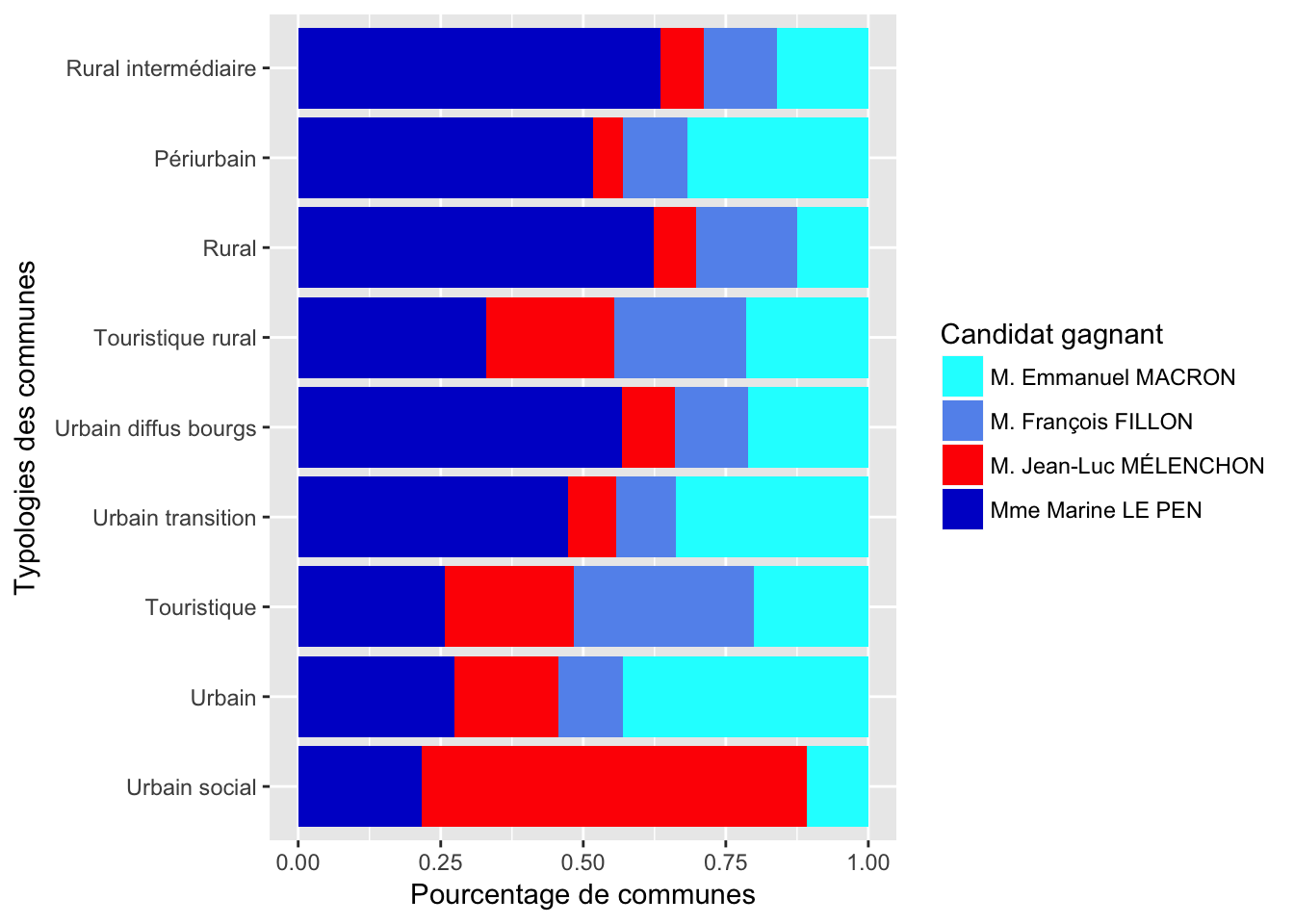
3.1 Typologies des commnunes
Pour voir les pourcentages
NB: on compte en nombre de communes, et non pas la population.
On peut classer les typopologies selon la taille de la population.
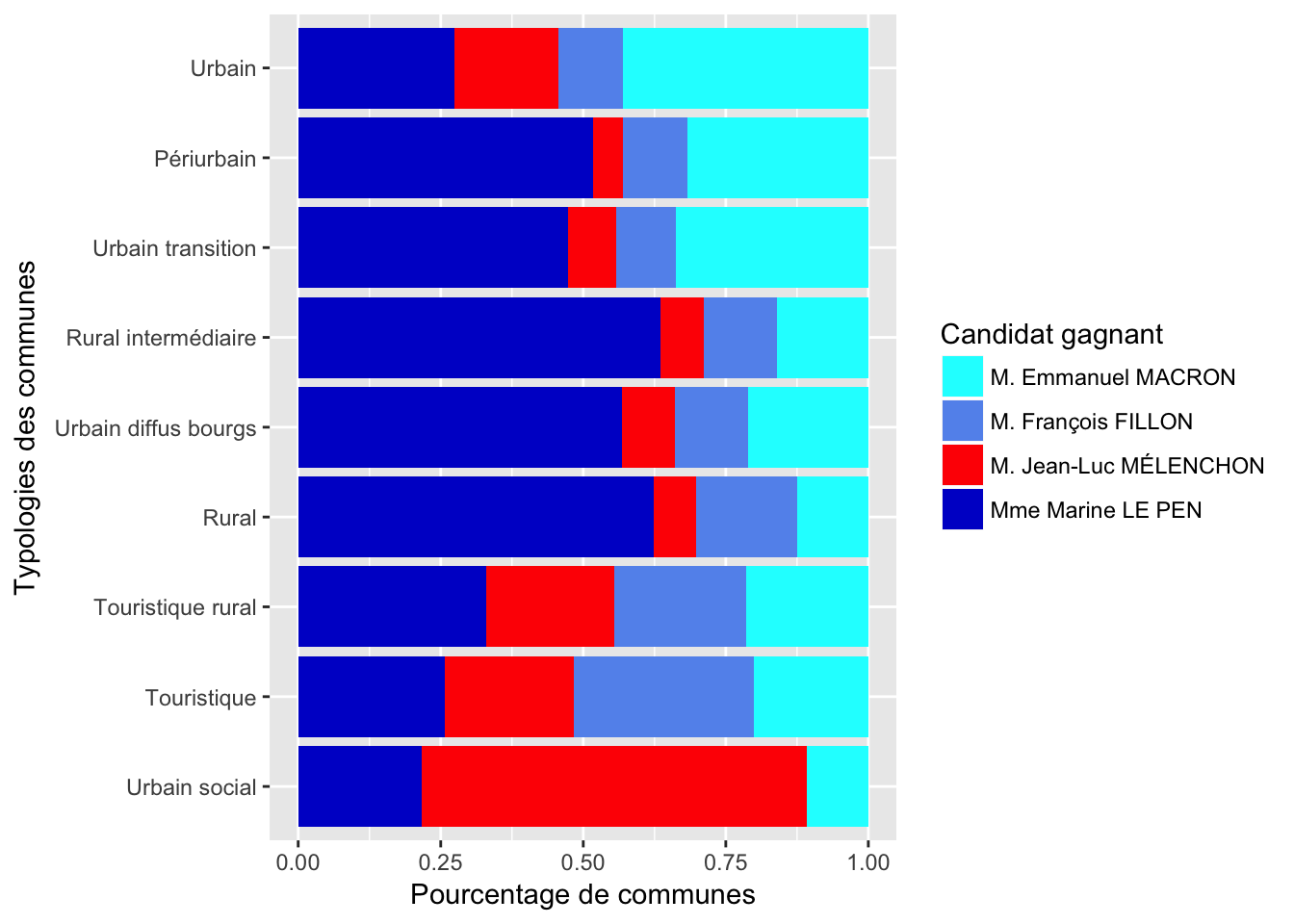
On pourrait représenter la largeur des barres par la population, mais comme certaines typologies représentent une taille de population, on risque de ne rien voir.
Aussi pour combiner plusieurs variables (population, nombres de communes, voix), on pourrait utiliser un treemap.
3.2 Densité popoulation et revenu
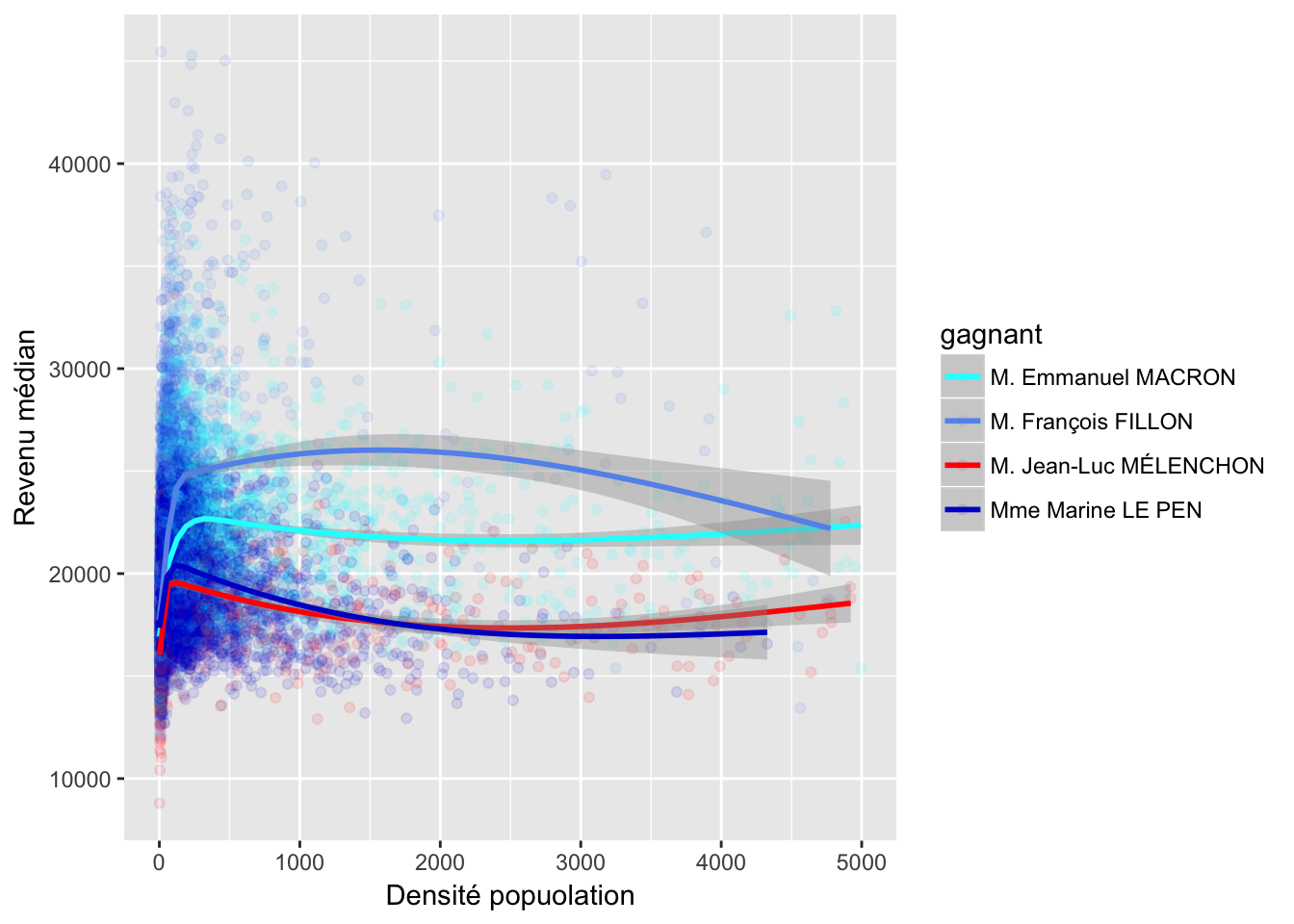
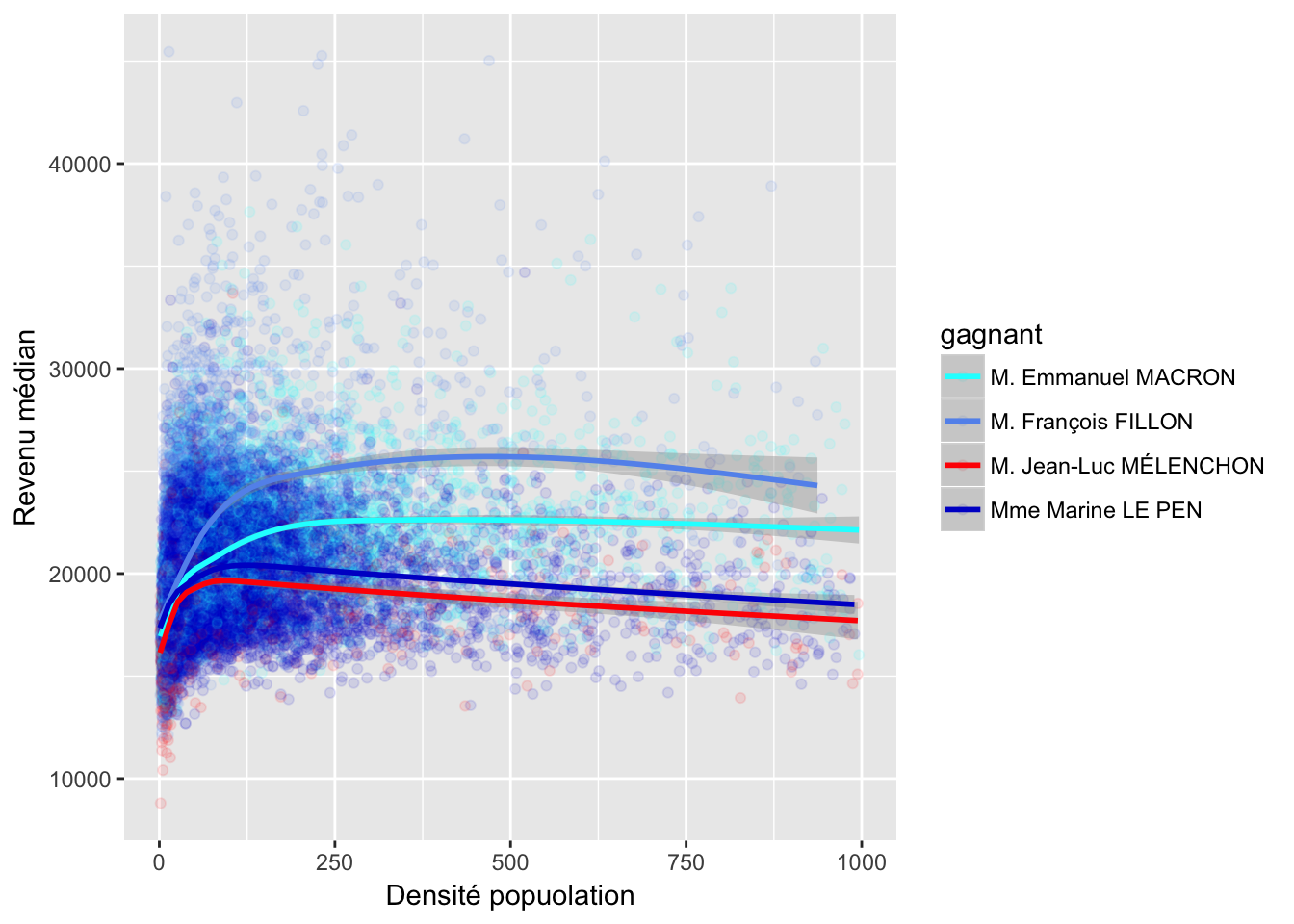
3.3 Chômage
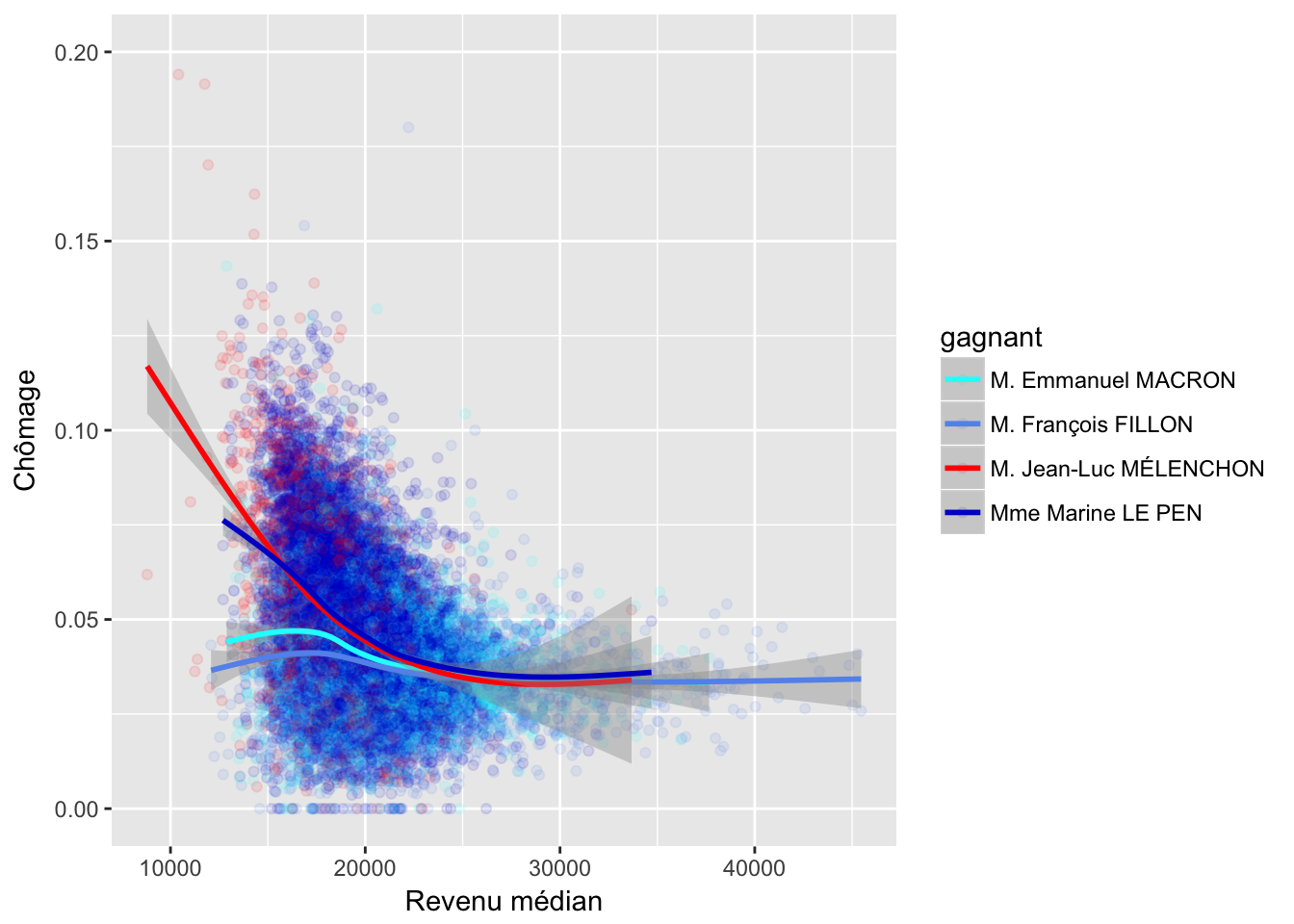
3.4 Taux immigrés
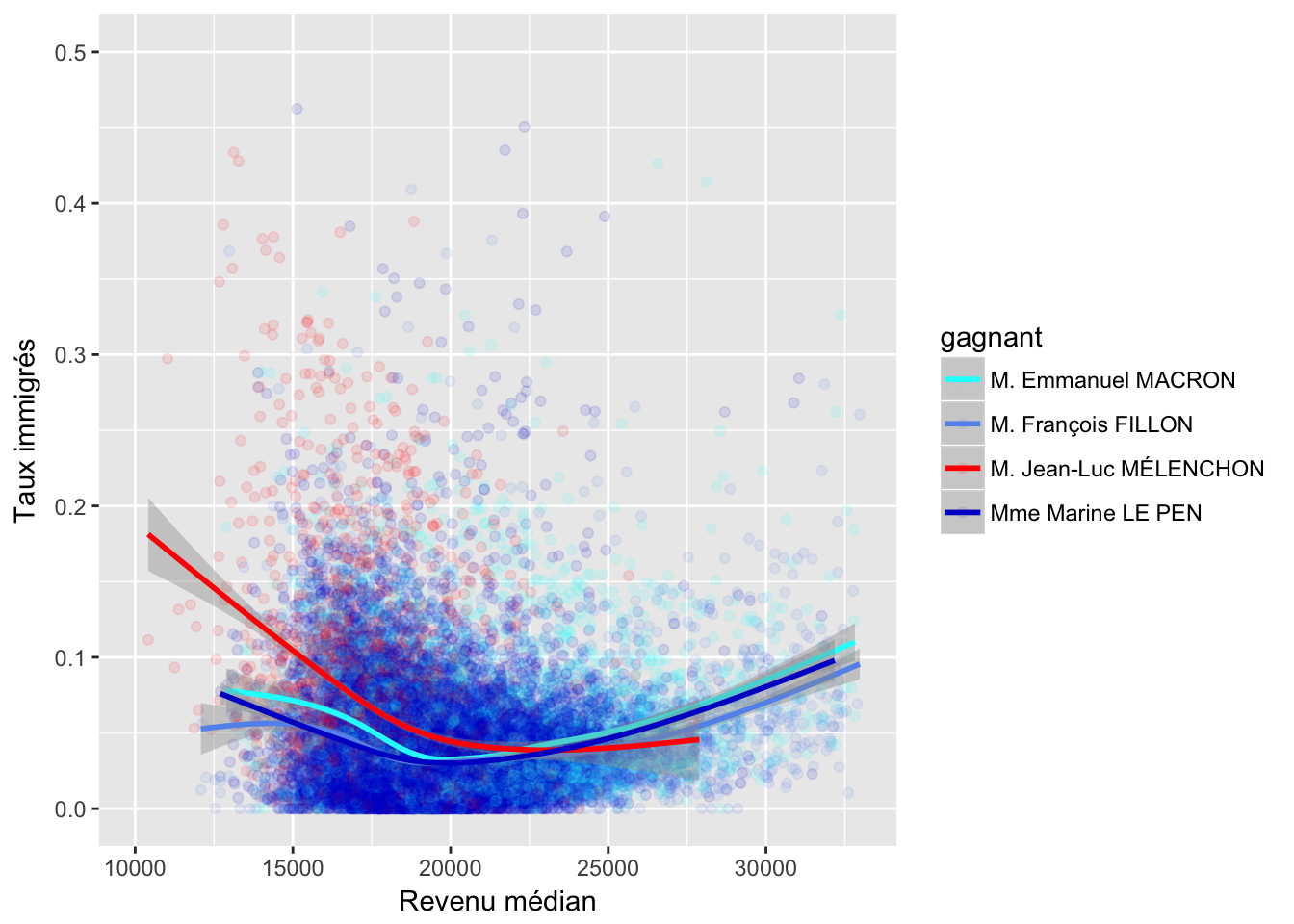
4 Ecarts candidat
Dans la section précédante, on analyse les gagnants par commune. Cependant, l’écart du premier peut-être plus ou moins important par rapport au deuxième. On peut analyser les communes où un score est particulièrement important, cela permet de mieux comprendre les profils de personnes qui votent pour un candidat en particulier.
Par exemple, comme on a vu que le score pour Marine Le Pen était volatile, on peut analyser les communes où son score est supérieur à 40%
4.1 Revenus
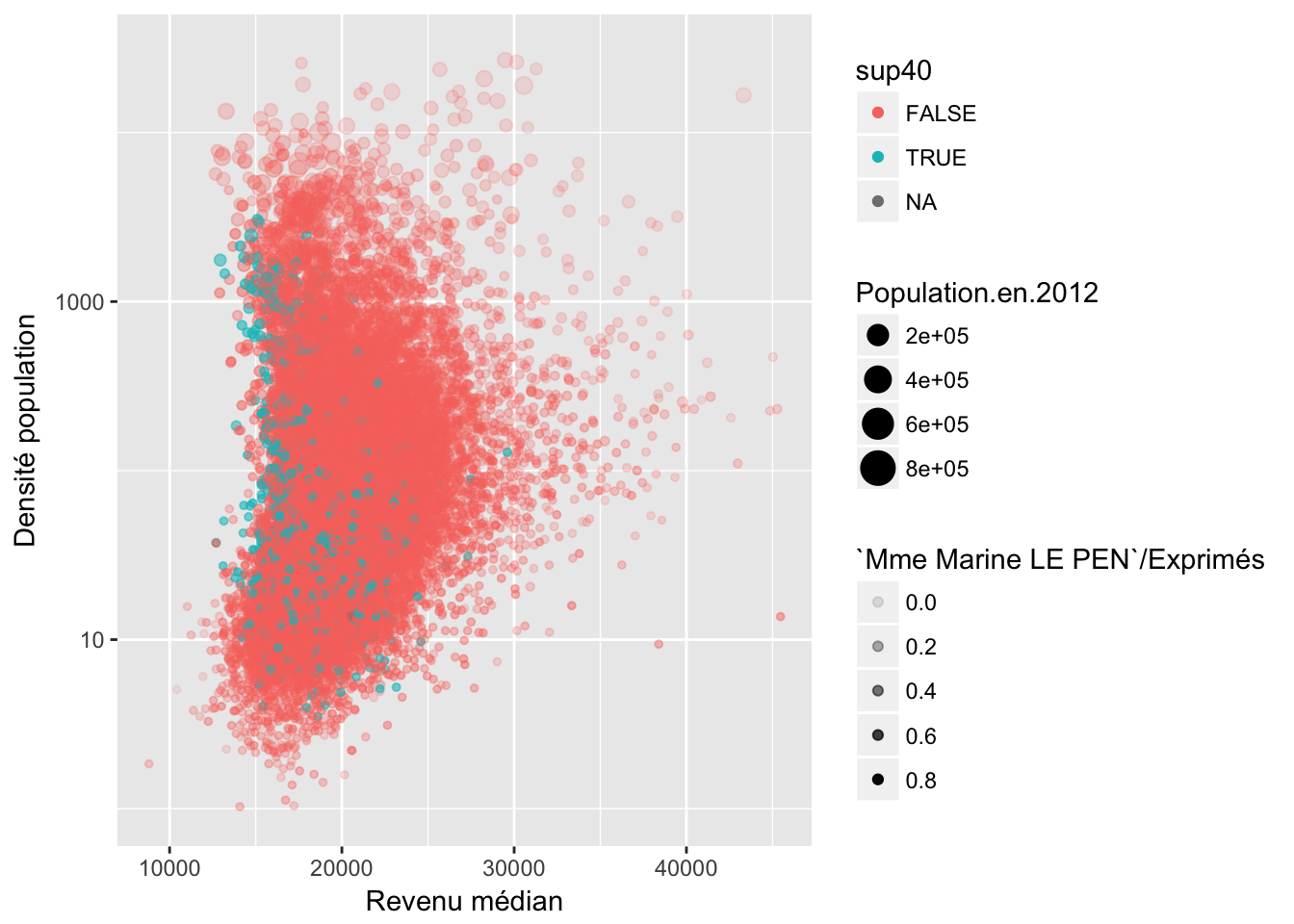
4.2 Ménages
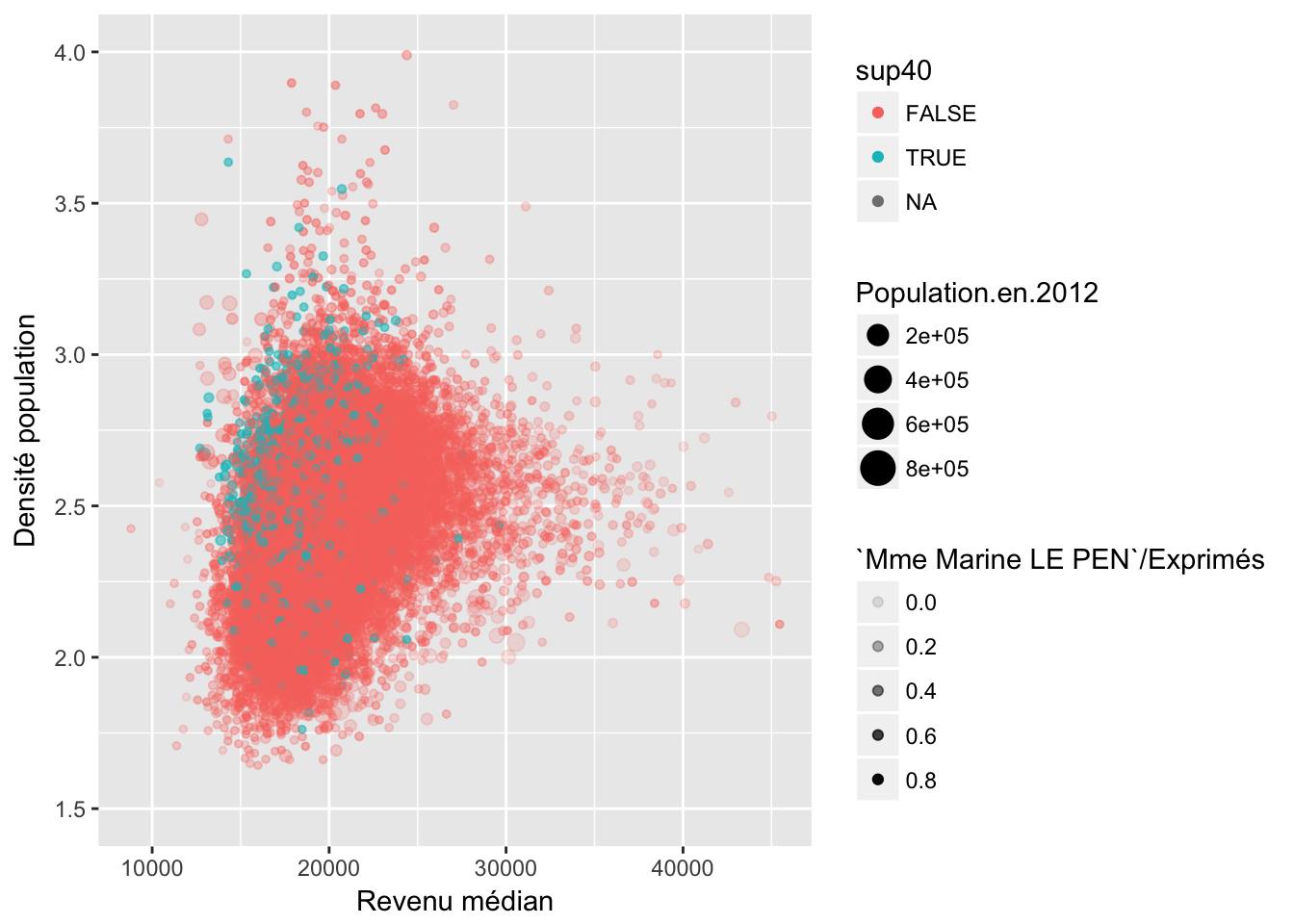
4.3 Immigration
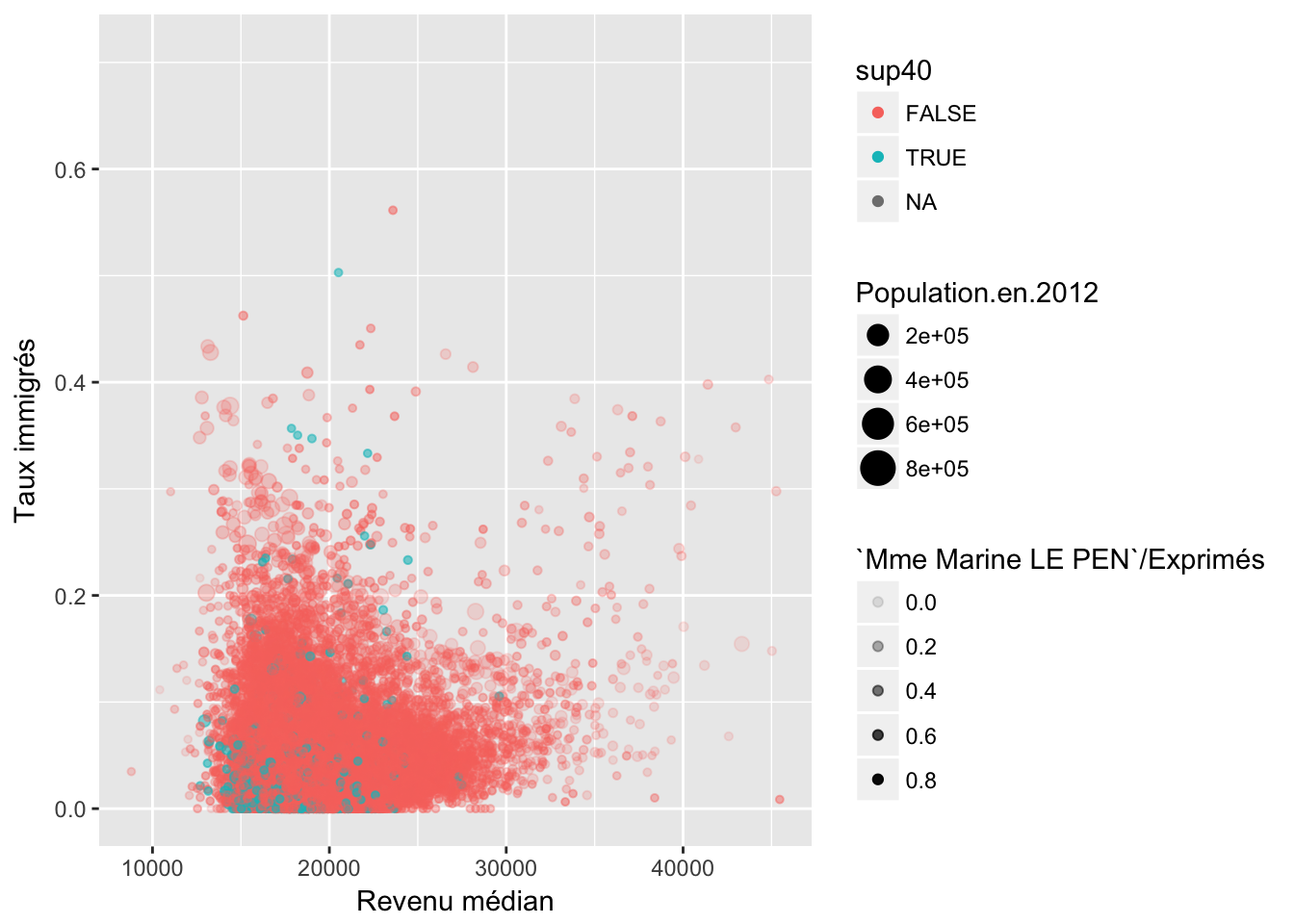
5 Second tour
N’oubliez pas d’aller voter le 7 mai 2017.
6 Démarche
Quelques commentaires sur la façon de réaliser ces quelques graphiques.
6.1 Questions
Vis-à-vis des données des résultats du premier tour, on peut avoir plusieurs objectifs :
- Objectif informatif: informer les électeurs des résultats de l’élection. On peut donner des résultats brutes, pour qu’un électeur donné puisse les consulter. Cependant, il serait plus intéressant de donner quelques interprétations.
- Objectif prédictif: si on arrive à bien modéliser les résultats de votes en fonction des caractéristiques de la population, on pourrait alors faire des prédictions en fonction de ces caractéristiques et comprendre le profil d’électeurs qui voteraient pour un candidat en particulier.
- Stratégie de campagne: les candidats peuvent utiliser ces données pour mieux comprendre leurs forces et faiblesses pour mieux orienter les lieux et axes de communication.
6.2 Sources de données
Avec le mouvement Open Data, on voit que certaines villes ont commencé à ouvrir des bases de données. Le site de data.gouv centralise un certain nombre de données. Pour les résultats de l’élection par commune, ou par bureau de votes au niveau national, à ma connaissance, il n’y a malheureusement pas une base propre qui existe.
Résultats officels 2017
Les données officielles des élections sont sur le site du Ministère de l’intérieur: élection présidentielle 2017. Malheureusement, il n’existe de fichier à télécharger directement.
Il existe un fichier sur data gouv, mais les données sont par canton de vote.
Pour le département du 92, on a les données structurées. De plus, il y a les élections historiques : élections présidentielles par commune dans le 92
Historique des élections
Cet article par des sources de données.
Visualisation
Par bureaux de votes
On a les résultats de votes par bureau de vote en 2012
Les résultats par bureau de vote à paris en 2017 sur cette carte, je n’ai pas trouvé la source de données.
Données statistiques de la population
On peut en trouver plein, et il faut un peut nettoyer, concaténer avant de pouvoir utiliser, un fichier que j’ai utilisé est un résumé statistique
6.3 Analyse des données
Exploration des données 2017
Ce qui a été fait, c’est juste une exploration visuelle des données pour 2017.
Analyse historique
Si on prend en compte l’évolution temporelle, on peut déjà mieux comprendre. D’ailleurs les données statistiques de la population datent de 2012.
Segmentation
Il est possible de trouver les profils de population qui votent plus pour un candidat particulier.
Prédictions
Avec un certain nombre de variables, on peut construire un algorithme (GLM ou arbre de décision) pour prédire les votes.
J’ai entendu certains instituts de sondage dire: on choisit un certain nombre de communes qui ont une bonne représentativité de la France pour estimer les résultats d’élections.
J’imagine que cela que veut dire que ce sont les communes qui ont des caractéristiques similaires par rapport au niveau national. Si on sait comment certaines caractéristiques influent sur les résultats, on pourrait sans doute améliorer l’estimation, en prenant en comptes toutes les communes avec les caractéristiques correspondantes.
6.4 Visualisation
La visualisation permet de mieux comprendre certaines relations de façon efficace.
Visualisation des voix par candidat
La première partie consistait à visualiser la relation entre les voix d’un candidat et une caractéristique. La couleur représente une troisième dimension. Il est possible de représenter une autre variable. Il y a une quatrième variable représentée pas la taille des points, mais c’est peu illisble à cause du nombre important de points. Il est possible de représenter encore une variable avec la transparence.
Gagnant par commune
Si on considère le gagnant, il est alors possible de mettre deux variables sur le plan.
6.5 Conclusions
Objectif informatique
Les graphiques, les statistiques ne sont que des inputs, donner des commentaires pertinents restent un travail d’importance, qui n’est pas été fait.
Pour aller plus loin, par exemple, on peut utiliser les données statistiques sur la popoulation pour mieux calculer une prime d’assurance habitation.
Copyright © 2016 Blog de Kezhan Shi